Documents
Poster
RD-OPTIMIZED 3D PLANAR MODEL RECONSTRUCTION & ENCODING FOR VIDEO COMPRESSION
- Citation Author(s):
- Submitted by:
- CHENG YANG
- Last updated:
- 14 October 2018 - 10:50pm
- Document Type:
- Poster
- Document Year:
- 2018
- Event:
- Presenters:
- Seishi Takamura
- Paper Code:
- 2600
- Categories:
- Log in to post comments
Conventional video coding approaches follow a hybrid motion prediction / residual transform coding paradigm, which limits the discovery of redundancy to individual pairs of video frames.
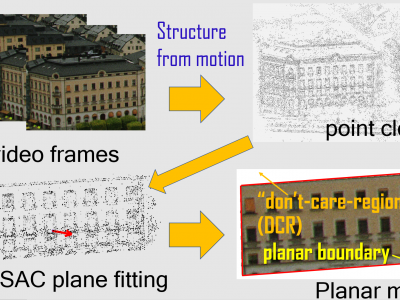
On the other hand, computer vision techniques like structure-from-motion (SfM) have long exploited redundancy across a large group of frames to estimate a rigid 3D object structure.
In this paper, leveraging on previous SfM techniques, we construct a rate-distortion (RD) optimized 3D planar model from a target spatial region in a frame group as a unified signal predictor for these frames.
The prediction accuracy of the model is optimally traded off with the cost of coding such representation as side information (SI).
Specifically, we approximate a roughly flat spatial region in the video as a 2D plane in 3D space, and project pixels from the frame group to a 2D grid on the plane with appropriate density.
The boundary of the irregularly shaped pixel body on the plane is first coded using arithmetic edge coding (AEC), and then the body is encapsulated into a tight-fitting rectangular region, which is encoded as an intra-frame using HEVC.
The pixels inside the rectangle but outside the pixel body---called don't care region (DCR)---are filled optimally by minimizing an $l_1$-norm of the transform coefficients using linear programming.
Experimental results show that the RD-optimized planar model improves coding performance over native HEVC implementation.

