
- Read more about Source Coding of Audio Signals with a Generative Model
- 1 comment
- Log in to post comments
These are the slides from the video presentation at ICASSP 2020 of the paper "Source Coding of Audio Signals with a Generative Model".
- Categories:
 77 Views
77 Views
- Read more about Source Coding of Audio Signals with a Generative Model
- 2 comments
- Log in to post comments
We consider source coding of audio signals with the help of a generative model. We use a construction where a waveform is first quantized, yielding a finite bitrate representation. The waveform is then reconstructed by random sampling from a model conditioned on the quantized waveform. The proposed coding scheme is theoretically analyzed. Using SampleRNN as the generative model, we demonstrate that the proposed coding structure provides performance competitive with state-of-the-art source coding tools for specific categories of audio signals.
- Categories:
120 Views
- Read more about A high efficient cascade coder with predictor blending method for lossless audio compression
- Log in to post comments
In this paper, the improvement of the cascaded prediction method was presented. The prediction method with backward adaptation and extended Ordinary Least Square (OLS+) was presented. An own approach to implementation of the effective context-dependent constant component removal block was used. Also the improved adaptive arithmetic coder with short, medium and long-term adaptation was used and the experiment was carried out comparing the results with other known lossless audio coders against which our method obtained the best efficiency.
- Categories:
31 Views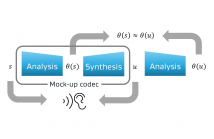
- Read more about Learning about perception of temporal fine structure by building audio codecs
- Log in to post comments
This is a poster presented Thursday August 22, 2019 at the International Symposium on Auditory and Audiological Research (ISAAR). https://www.isaar.eu/index.php
SP.72 - Learning about perception of temporal fine structure by building audio codecs
- Categories:
101 Views
- Read more about EVS AND OPUS AUDIO CODERS PERFORMANCE EVALUATION FOR ORIENTAL AND ORCHESTRAL MUSICAL INSTRUMENTS
- Log in to post comments
In modern telecommunication systems the channel bandwidth and the quality of the reconstructed decoded audio signals are considered as major telecommunication resources. New speech or audio coders must be carefully designed and implemented to meet these requirements. EVS and OPUS audio coders are new coders which used to improve the quality of the reconstructed audio signal at different output bitrates. These coders can operate with different input signal type. The performance of these coders must be evaluated in terms of the quality of the reconstructed signals.
- Categories:
70 Views
- Read more about AUDIO CODING BASED ON SPECTRAL RECOVERY BY CONVOLUTIONAL NEURAL NETWORK
- Log in to post comments
This study proposes a new method of audio coding based on spectral recovery, which can enhance the performance of transform audio coding. An encoder represents spectral information of an input in a time-frequency domain and transmits only a portion of it so that the remaining spectral information can be recovered based on the transmitted information. A decoder recovers the magnitudes of missing spectral information using a convolutional neural network. The signs of missing spectral information are either transmitted or randomly assigned, according to their importance.
- Categories:
22 Views
- Read more about Speaker-dependent WaveNet-based delay-free ADPCM speech coding
- Log in to post comments
This paper proposes a WaveNet-based delay-free adaptive differential pulse code modulation (ADPCM) speech coding system. The WaveNet generative model, which is a stateof-the-art model for neural-network-based speech waveform synthesis, is used as the adaptive predictor in ADPCM. To further improve speech quality, mel-cepstrum-based noise shaping and postfiltering were integrated with the proposed ADPCM system.
poster.pdf
- Categories:
29 Views
- Read more about Immersive Audio Coding for Virtual Reality Using a Metadata-Assisted Extension of the 3GPP EVS Codec
- Log in to post comments
Virtual Reality (VR) audio scenes may be composed of a very large number of audio elements, including dynamic audio objects, fixed audio channels and scene-based audio elements such as Higher Order Ambisonics (HOA).
VRStream.pdf
- Categories:
65 Views
- Read more about WAVENET BASED LOW RATE SPEECH CODING
- Log in to post comments
Traditional parametric coding of speech facilitates low rate but provides poor reconstruction quality because of the inadequacy of the model used. We describe how a WaveNet generative speech model can be used to generate high quality speech from the bit stream of a standard parametric coder operating at 2.4 kb/s. We compare this parametric coder with a waveform coder based on the same generative model and show that approximating the signal waveform incurs a large rate penalty.
- Categories:
45 Views
- Read more about ADAPTIVE CODING OF NON-NEGATIVE FACTORIZATION PARAMETERS WITH APPLICATION TO INFORMED SOURCE SEPARATION
- Log in to post comments
Informed source separation (ISS) uses source separation for extracting audio objects out of their downmix given some pre-computed parameters. In recent years, non-negative tensor factorization (NTF) has proven to be a good choice for compressing audio objects at an encoding stage. At the decoding stage, these parameters are used to separate the downmix with Wiener-filtering. The quantized NTF parameters have to be encoded to a bitstream prior to transmission.
- Categories:
11 Views