
- Read more about Infant Voice Diarization presentation slides
- Log in to post comments
- Categories:
 2 Views
2 Views
We propose a deep graph approach to address the task of speech emotion recognition. A compact, efficient and scalable way to represent data is in the form of graphs. Following the theory of graph signal processing, we propose to model speech signal as a cycle graph or a line graph. Such graph structure enables us to construct a Graph Convolution Network (GCN)-based architecture that can perform an accurate graph convolution in contrast to the approximate convolution used in standard GCNs.
- Categories:
33 Views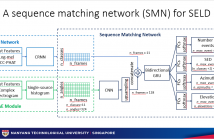
- Read more about A Sequence Matching Network for Polyphonic Sound Event Localization and Detection
- Log in to post comments
Polyphonic sound event detection and direction-of-arrival estimation require different input features from audio signals. While sound event detection mainly relies on time-frequency patterns, direction-of-arrival estimation relies on magnitude or phase differences between microphones. Previous approaches use the same input features for sound event detection and direction-of-arrival estimation, and train the two tasks jointly or in a two-stage transfer-learning manner.
- Categories:
66 Views
- Read more about DEEP EMBEDDINGS FOR RARE AUDIO EVENT DETECTION WITH IMBALANCED DATA
- Log in to post comments
In this paper, we present a method to handle data imbalance for classification with neural networks, and apply it to acoustic event detection (AED) problem. The common approach to tackle data imbalance is to use class-weights in the objective function while training. An existing more sophisticated approach is to map the input to clusters in an embedding space, so that learning is locally balanced by incorporating inter-cluster and inter-class margins. On these lines, we propose a method to learn the embedding using a novel objective function, called triple-header cross entropy.
- Categories:
16 Views
- Read more about Language Transfer of Audio Word2Vec: Learning Audio Segment Representations without Target Language Data
- Log in to post comments
- Categories:
28 Views
- Read more about CONTENT-BASED REPRESENTATIONS OF AUDIO USING SIAMESE NEURAL NETWORKS
- Log in to post comments
In this paper, we focus on the problem of content-based retrieval for
audio, which aims to retrieve all semantically similar audio recordings
for a given audio clip query. This problem is similar to the
problem of query by example of audio, which aims to retrieve media
samples from a database, which are similar to the user-provided example.
We propose a novel approach which encodes the audio into
a vector representation using Siamese Neural Networks. The goal is
to obtain an encoding similar for files belonging to the same audio
- Categories:
9 Views
- Read more about Knowledge Transfer From Weakly Labeled Audio Using Convolutional Neural Network For Sound Events and Scenes
- Log in to post comments
- Categories:
32 Views
- Read more about CONTENT-BASED REPRESENTATIONS OF AUDIO USING SIAMESE NEURAL NETWORKS
- Log in to post comments
In this paper, we focus on the problem of content-based retrieval for
audio, which aims to retrieve all semantically similar audio recordings
for a given audio clip query. This problem is similar to the
problem of query by example of audio, which aims to retrieve media
samples from a database, which are similar to the user-provided example.
We propose a novel approach which encodes the audio into
a vector representation using Siamese Neural Networks. The goal is
to obtain an encoding similar for files belonging to the same audio
- Categories:
4 Views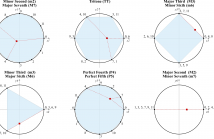
In this paper we present the INESC Key Detection (IKD) system which incorporates a novel method for dynamically biasing key mode estimation using the spatial displacement of beat-synchronous Tonal Interval Vectors (TIVs). We evaluate the performance of the IKD system at finding the global key on three annotated audio datasets and using three key-defining profiles.
- Categories:
8 Views