
- Read more about DEEP COLOR CONSTANCY USING TEMPORAL GRADIENT UNDER AC LIGHT SOURCES
- Log in to post comments
With the invention of electric bulbs, human has been living under various illuminant environments. Since the alternative current (AC) power is used for supplier of electric bulbs, intensity difference between consecutive video frames can be captured with high-speed camera. While most of conventional methods focus on only spatial information of a single image, we propose a deep spatio-temporal color constancy method. To exploit the temporal feature from high-speed video, maximum gradient map is fed into the proposed network.
- Categories:
 5 Views
5 Views

- Read more about Fast Inverse Mapping of Face GANs
- Log in to post comments
Generative adversarial networks (GANs) synthesize realistic images from random latent vectors. While many studies have explored various training configurations and architectures for GANs, the problem of inverting the generator of GANs has been inadequately investigated. We train a ResNet architecture to map given faces to latent vectors that can be used to generate faces nearly identical to the target. We use a perceptual loss to embed face details in the recovered latent vector while maintaining visual quality using a pixel loss.
- Categories:
4 Views
- Read more about Efficient Real-Time Video Stabilization with A Novel Least Squares Formulation
- Log in to post comments
We present a novel video stabilization algorithm (LSstab) that removes unwanted motions in real-time. LSstab is based on a novel least squares formulation of the smoothing cost function to alleviate the undesirable camera jitter. A recursive least square solver is derived to minimize the smoothing cost function with an O(N) computation complexity. LSstab is evaluated using a suite of publicly available videos against the state of the art video stabilization methods. Results show LSstab reaches comparable or better performance, achieving real-time processing speed when a GPU is used.
- Categories:
15 Views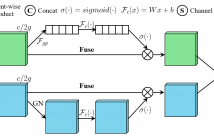
- Read more about SA-Net: Shuffle Attention for Deep Convolutional Neural Networks
- Log in to post comments
Attention mechanisms, which enable a neural network to accurately focus on all the relevant elements of the input, have become an essential component to improve the performance of deep neural networks. There are mainly two attention mechanisms widely used in computer vision studies, spatial attention and channel attention, which aim to capture the pixel-level pairwise relationship and channel dependency, respectively. Although fusing them together may achieve better performance than their individual implementations, it will inevitably increase the computational overhead.
poster.pdf
- Categories:
39 Views
- Read more about CANET: CONTEXT-AWARE LOSS FOR DESCRIPTOR LEARNING
- Log in to post comments
- Categories:
6 Views
- Read more about An Empirical Analysis of Recurrent Learning Algorithms In Neural Lossy Image Compression Systems.
- 1 comment
- Log in to post comments
Prior work on image compression has focused on optimizing models to achieve better reconstruction at lower bit rates. These approaches are focused on creating sophisticated architectures that enhance encoder or decoder performance. In some cases, there is the desire to jointly optimize both along with a designed form of entropy encoding. In some instances, these approaches result in the creation of many redundant components, which may or may not be useful.
- Categories:
52 Views