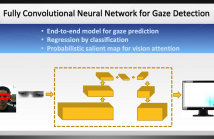
- Read more about Estimation of gaze region using two dimensional probabilistic maps constructed using convolutional neural networks
- Log in to post comments
Predicting the gaze of a user can have important applications in hu- man computer interactions (HCI). They find applications in areas such as social interaction, driver distraction, human robot interaction and education. Appearance based models for gaze estimation have significantly improved due to recent advances in convolutional neural network (CNN). This paper proposes a method to predict the gaze of a user with deep models purely based on CNNs.
- Categories:
 34 Views
34 Views
- Read more about A REAL-TIME DEEP NETWORK FOR CROWD COUNTING
- Log in to post comments
Automatic analysis of highly crowded people has attracted extensive attention from computer vision research. Previous approaches for crowd counting have already achieved promising performance across various benchmarks. However, to deal with the real situation, we hope the model run as fast as possible while keeping accuracy. In this paper, we propose a compact convolutional neural network for crowd counting which learns a more efficient model with a small number of parameters.
- Categories:
16 Views
- Read more about View-angle Invariant Object Monitoring Without Image Registration
- Log in to post comments
Object monitoring can be performed by change detection algorithms. However, for the image pair with a large perspective difference, the change detection performance is usually impacted by inaccurate image registration. To address the above difficulties, a novel object-specific change detection approach is proposed for object monitoring in this paper. In contrast to traditional approaches, the proposed approach is robust to view angle variation and does not require explicit image registration. Experiments demonstrate the effectiveness and advantages of the proposed approach.
- Categories:
21 Views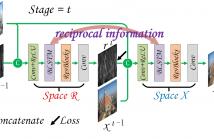
Single image deraining has been widely studied in recent years. Motivated by residual learning, most deep learning based deraining approaches devote research attention to extracting rain streaks, usually yielding visual artifacts in final deraining images. To address this issue, we in this paper propose bilateral recurrent network (BRN) to simultaneously exploit rain streak layer and background image layer. Generally, we employ dual residual networks (ResNet) that are recursively unfolded to sequentially extract rain streaks and predict clean background image.
BRN_slides.pdf
- Categories:
33 Views
- Read more about JOINT ENHANCEMENT AND DENOISING OF LOW LIGHT IMAGES VIA JND TRANSFORM
- Log in to post comments
Low light images suffer from low dynamic range and severe noise due to low signal-to-noise ratio (SNR). In this paper, we propose joint enhancement and denoising of low light images via justnoticeable-difference (JND) transform. We achieve contrast enhancement and noise reduction simultaneously based on human visual perception. First, we perform contrast enhancement based on perceptual histogram to effectively allocate a dynamic range while preventing over-enhancement. Second, we generate JND map based on an HVS response model from foreground and background luminance, called JND transform.
- Categories:
57 Views
- Read more about Look globally, age locally: Face aging with an attention mechanism
- 1 comment
- Log in to post comments
Face aging is of great importance for cross-age recognition and entertainment-related applications. Recently, conditional generative adversarial networks (cGANs) have achieved impressive results for facial aging. Existing cGANs-based methods usually require a pixel-wise loss to keep the identity and background consistent. However, minimizing the pixel-wise loss between the input and synthesized images likely resulting in a ghosted or blurry face.
- Categories:
18 Views
- Read more about Graph Neural Net using Analytical Graph Filters and Topology Optimization for Image Denoising
- Log in to post comments
While convolutional neural nets (CNN) have achieved remarkable performance for a wide range of inverse imaging applications, the filter coefficients are computed in a purely data-driven manner and are not explainable. Inspired by an analytically derived CNN by Hadji et al., in this paper we construct a new layered graph convolutional neural net (GCNN) using GraphBio as our graph filter.
- Categories:
74 Views
- Read more about Mr Nikolajs Skuratovs
- Log in to post comments
In this paper we consider the problem of recovering a signal x of size N from noisy and compressed measurements y = A x + w of size M, where the measurement matrix A is right-orthogonally invariant (ROI). Vector Approximate Message Passing (VAMP) demonstrates great reconstruction results for even highly ill-conditioned matrices A in relatively few iterations. However, performing each iteration is challenging due to either computational or memory point of view.
- Categories:
29 Views
This demo will showcase our video-to-audio model which attempts to reconstruct speech from short videos of spoken statements. Our model does so in a completely end-to-end manner where raw audio is generated based on the input video. This approach bypasses the need for separate lip-reading and text-to-speech models. The advantage of such an approach is that it does not require large transcribed datasets and it is not based on intermediate representations like text which remove any intonation and emotional content from the speech.
- Categories:
101 Views
- Read more about Multispectral Fusion of RGB and NIR Images Using Weighted Least Squares and Alternating Guidance
- Log in to post comments
In low light condition, color (RGB) images captured by camera contain much noise and loss of details and color. However, near infrared (NIR) images are robust to noise and have clear textures without color. In this paper, we propose multi-spectral fusion of RGB and NIR images using weighted least squares (WLS) and alternating guidance. Low light RGB images provide coarse image structure and color, while NIR images offer clear textures in a short distance. Since they are complementary, we adopt alternating guidance for fusion of RGB and NIR images based on WLS.
- Categories:
49 Views