
The International Conference on Image Processing (ICIP), sponsored by the IEEE Signal Processing Society, is the premier forum for the presentation of technological advances and research results in the fields of theoretical, experimental, and applied image and video processing. ICIP has been held annually since 1994, brings together leading engineers and scientists in image and video processing from around the world. Visit website.

- Read more about DEPTH FROM GAZE
- Log in to post comments
Eye trackers are found on various electronic devices. In this paper, we propose to exploit the gaze information acquired by an eye tracker for depth estimation. The data collected from the eye tracker in a fixation interval are used to estimate the depth of a gazed object. The proposed method can be used to construct a sparse depth map of an augmented reality space. The resulting depth map can be applied to, for example, controlling the visual information displayed to the viewer.
Poster.pdf
- Categories:
 26 Views
26 Views
This work presents an automatic method for optical flow inpainting. Given a video, each frame domain is endowed with a Riemannian metric based on the video pixel values. The missing optical flow is recovered by solving the Absolutely Minimizing Lipschitz Extension (AMLE) partial differential equation on the Riemannian manifold. An efficient numerical algorithm is proposed using eikonal operators for nonlinear elliptic partial differential equations on a finite graph.
- Categories:
11 Views
- Read more about A STUDY ON THE 4D SPARSITY OF JPEG PLENO LIGHT FIELDS USING THE DISCRETE COSINE TRANSFORM
- Log in to post comments
In this work we study the 4D sparsity of light fields using as main tool the 4D-Discrete Cosine Transform. We analyze the two JPEG Pleno light field datasets, namely the lenslet-based and the High- Density Camera Array (HDCA) datasets. The results suggest that the lenslets datasets exhibit a high 4D redundancy, with a larger inter-view sparsity than the intra-view one. For the HDCA datasets, there is also 4D redundancy worthy to be exploited, yet in a smaller degree. Unlike the lenslets case, the intra-view redundancy is much larger than the inter-view one.
icip-2018-4d-dct.pdf
- Categories:
20 Views
- Read more about TS-Net: Combining Modality Specific and Common Features for Multimodal Patch Matching
- Log in to post comments
- Categories:
4 Views
- Read more about GESTALT INTEREST POINTS WITH A NEURAL NETWORK FOR MAKEUP-ROBUST FACE RECOGNITION
- Log in to post comments
In this paper, we propose a novel approach for the domain of makeup-robust face recognition. Most face recognition schemes usually fail to generalize well on these data where there is a large difference between the training and testing sets, e.g., makeup changes. Our method focuses on the problem of determining whether face images before and after makeup refer to the same identity. The work on this fundamental research topic benefits various real-world applications, for example automated passport control, security in general, and surveillance.
Poster_A1.pdf
- Categories:
17 Views
This work presents a thresholding method for processing the predicted samples in the state-of-the-art High Efficiency Video Coding (HEVC) standard. The method applies an integer-based approximation of the discrete cosine transform to an extended prediction block and sets transform coefficients beneath a certain threshold to zero. Transforming back into the sample domain yields the improved prediction signal. The method is incorporated into a software implementation that is conforming to the HEVC standard and applies to both intra and inter predictions.
- Categories:
12 Views
Visual attention allows the human visual system to effectively deal with the huge flow of visual information acquired by the retina. Since the years 2000, the human visual system began to be modelled in computer vision to predict abnormal, rare and surprising data. Attention is a product of the continuous interaction between bottom-up (mainly feature-based) and top-down (mainly learning-based) information. Deep-learning (DNN) is now well established in visual attention modelling with very effective models.
- Categories:
6 Views
- Read more about A Multicore Convex Optimization Algorithm with Applications to Video Restoration
- Log in to post comments
In this paper, we present a new distributed algorithm for minimizing a sum of non-necessarily differentiable convex
functions composed with arbitrary linear operators. The overall cost function is assumed strongly convex.
- Categories:
7 Views
- Read more about FLOWFIELDS++: ACCURATE OPTICAL FLOW CORRESPONDENCES MEET ROBUST INTERPOLATION
- Log in to post comments
- Categories:
14 Views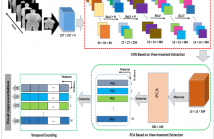
- Read more about DEPTH HUMAN ACTION RECOGNITION BASED ON CONVOLUTION NUERAL NETWORKS AND PRINCIPAL COMPONENT ANALYSIS
- Log in to post comments
In this work, we address human action recognition problem under viewpoint variation. The proposed model is formulated by wisely combining convolution neural network (CNN) model with principle component analysis (PCA). In this context, we pass real depth videos through a CNN model in a frame-wise manner. The view invariant features are extracted by employing convolution layers as mid-outputs and considered as 3D nonnegative tensors.
- Categories:
15 Views