
Welcome to ISCSLP 2016 - October 17-20, 2016, Tianjin, China
The ISCSLP will be hosted by Tianjin University. Tianjin has a reputation throughout China for being extremely friendly, safe and a place of delicious food. Welcome to Tianjin to attend the ISCSLP2016. The 10th International Symposium on Chinese Spoken Language Processing (ISCSLP 2016) will be held on October 17-20, 2016 in Tianjin. ISCSLP is a biennial conference for scientists, researchers, and practitioners to report and discuss the latest progress in all theoretical and technological aspects of spoken language processing. While the ISCSLP is focused primarily on Chinese languages, works on other languages that may be applied to Chinese speech and language are also encouraged. The working language of ISCSLP is English.
- Read more about Multi-Task Joint-Learning for Robust Voice Activity Detection
- Log in to post comments
Model based VAD approaches have been widely used and
achieved success in practice. These approaches usually cast
VAD as a frame-level classification problem and employ statistical
classifiers, such as Gaussian Mixture Model (GMM) or
Deep Neural Network (DNN) to assign a speech/silence label
for each frame. Due to the frame independent assumption classification,
the VAD results tend to be fragile. To address this
problem, in this paper, a new structured multi-frame prediction
DNN approach is proposed to improve the segment-level
- Categories:
 37 Views
37 Views- Read more about Senone I-Vectors for Robust Speaker Verification
- Log in to post comments
- Categories:
4 Views- Read more about Investigation of the Spatiotemporal Dynamics of the Brain during Perceiving Words
- Log in to post comments
To investigate the temporal dynamics and spatial representations in speech perception and processing, electroencephalograph (EEG) signals were recorded when subjects listening Chinese words and pseudo words.
poster-syk.pdf
- Categories:
21 Views
- Read more about An Interface Research on Rhetorical Structure and Prosody Features in Chinese Reading Texts
- Log in to post comments
This paper conducted an interface research on rhetorical and prosodic aspects of Chinese reading discourses within the Rhetorical Structure Theory (RST) framework. Ten discourses in 3 genres (Commentary, Narrative, and Descriptive) from the Annotated Speech Corpus of Chinese Discourse (ASCCD) were diagrammed in RST. The recordings from 5 males and 5 females were annotated and further analyzed acoustically and statistically by applying Praat and R.
- Categories:
9 Views- Read more about A Speaker-Dependent Deep Learning Approach to Joint Speech Separation and Acoustic Modeling for Multi-Talker Automatic Speech Recognition
- Log in to post comments
We propose a novel speaker-dependent (SD) approach to joint training of deep neural networks (DNNs) with an explicit speech separation structure for multi-talker speech recognition in a single-channel setting. First, a multi-condition training strategy is designed for a SD-DNN recognizer in multi-talker scenarios, which can significantly reduce the decoding runtime and improve the recognition accuracy over the approaches that use speaker-independent DNN models with a complicated joint decoding framework.
- Categories:
17 Views- Read more about Dialog State Tracking for Interview Coaching Using Two-Level LSTM
- Log in to post comments
This study presents an approach to dialog state tracking (DST) in an interview conversation by using the long short-term memory (LSTM) and artificial neural network (ANN). First, the techniques of word embedding are employed for word representation by using the word2vec model. Then, each input sentence is represented by a sentence hidden vector using the LSTM-based sentence model. The sentence hidden vectors for each sentence are fed to the LSTM-based answer model to map the interviewee’s answer to an answer hidden vector.
- Categories:
4 Views- Read more about Dialog State Tracking for Interview Coaching Using Two-Level LSTM
- Log in to post comments
This study presents an approach to dialog state tracking (DST) in an interview conversation by using the long short-term memory (LSTM) and artificial neural network (ANN). First, the techniques of word embedding are employed for word representation by using the word2vec model. Then, each input sentence is represented by a sentence hidden vector using the LSTM-based sentence model. The sentence hidden vectors for each sentence are fed to the LSTM-based answer model to map the interviewee’s answer to an answer hidden vector.
- Categories:
7 Views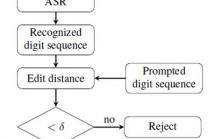
- Read more about Digit-dependent Local I-Vector for Text-Prompted Speaker Verification with Random Digit Sequences
- Log in to post comments
The widely adopted i-vector performances well in text-independent speaker verification with long speech duration. How to integrate the state-of-the-art i-vector framework into the text-prompted speaker verification is addressed in this paper. To take advantage of the lexical information and enhance the performance for speaker verification with random digit sequences, this paper proposes to extract a set of digit-dependent local i-vectors from the utterance instead of extracting a single i-vector. The digit-dependent local i-vector is considered
- Categories:
11 ViewsThe paper proposed a method to realize a speech-to-gesture conversion for communication between normal and speech-impaired people. Keyword spotting was employed to recognize the keywords from input speech signals. At the same time, the three dimensional gesture models of keywords were built by 3D modeling technology according to the "Chinese sign language". The speech-to-gesture conversion was finally realized by playing the corresponding 3D gestures with OpenGL from the results of keyword spotting.
- Categories:
12 Views- Read more about Perceptual Evaluation of Natural and Synthesized Speech with Prosodic Focus in Mandarin Production of American Learners
- Log in to post comments
Natural and synthesized speech in L2 Mandarin produced by American English learners was evaluated by native Mandarin speakers to identify focus status and rate the naturalness of the speech. The results reveal that natural speech was recognized and rated better than synthesized speech, early learners’ speech better than late learners’ speech, focused sentences better than no-focus sentences, and initial focus and medial focus better than final focus. Tones of in-focus words interacted with focus status of the sentence and speaker group.
- Categories:
4 Views