
Welcome to ISCSLP 2016 - October 17-20, 2016, Tianjin, China
The ISCSLP will be hosted by Tianjin University. Tianjin has a reputation throughout China for being extremely friendly, safe and a place of delicious food. Welcome to Tianjin to attend the ISCSLP2016. The 10th International Symposium on Chinese Spoken Language Processing (ISCSLP 2016) will be held on October 17-20, 2016 in Tianjin. ISCSLP is a biennial conference for scientists, researchers, and practitioners to report and discuss the latest progress in all theoretical and technological aspects of spoken language processing. While the ISCSLP is focused primarily on Chinese languages, works on other languages that may be applied to Chinese speech and language are also encouraged. The working language of ISCSLP is English.
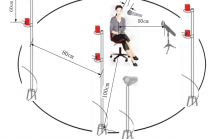
- Read more about A multi-channel/multi-speaker interactive 3D Audio-Visual Speech Corpus in Mandarin
- Log in to post comments
This paper presents a multi-channel/multi-speaker 3D audiovisual
corpus for Mandarin continuous speech recognition and
other fields, such as speech visualization and speech synthesis.
This corpus consists of 24 speakers with about 18k utterances,
about 20 hours in total. For each utterance, the audio
streams were recorded by two professional microphones in
near-field and far-field respectively, while a marker-based 3D
facial motion capturing system with six infrared cameras was
- Categories:
 11 Views
11 Views
- Read more about Unsupervised Speaker Adaptation of BLSTM-RNN for LVCSR Based on Speaker Code
- Log in to post comments
Recently, the speaker code based adaptation has been successfully expanded to recurrent neural networks using bidirectional Long Short-Term Memory (BLSTM-RNN) [1]. Experiments on the small-scale TIMIT task have demonstrated that the speaker code based adaptation is also valid for BLSTM-RNN. In this paper, we evaluate this method on large-scale task and introduce an error normalization method to balance the back-propagation errors derived from different layers for speaker codes. Meanwhile, we use singular value decomposition (SVD) method to conduct model compression.
- Categories:
11 Views
This paper presents a deep neural network (DNN)-based unit selection method for waveform concatenation speech synthesis using frame-sized speech segments. In this method, three DNNs are adopted to calculate target costs and concatenation costs respectively for selecting frame-sized candidate units. The first DNN is built in the same way as the DNN-based statistical parametric speech synthesis, which predicts target acoustic features given linguistic context inputs.
- Categories:
17 Views- Read more about Long Short-term Memory Recurrent Neural Network based Segment Features for Music Genre Classification
- Log in to post comments
In the conventional frame feature based music genre
classification methods, the audio data is represented by
independent frames and the sequential nature of audio is totally
ignored. If the sequential knowledge is well modeled and
combined, the classification performance can be significantly
improved. The long short-term memory(LSTM) recurrent
neural network (RNN) which uses a set of special memory
cells to model for long-range feature sequence, has been
successfully used for many sequence labeling and sequence
- Categories:
12 Views- Read more about Deep Neural Network for Robust Speech Recognition With Auxiliary Features From Laser-Doppler Vibrometer Sensor
- Log in to post comments
- Categories:
15 Views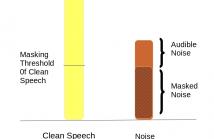
- Read more about Vector Taylor Series Expansion with Auditory Masking for Noise Robust Speech Recognition
- Log in to post comments
In this paper, we address the problem of speech recognition in
the presence of additive noise. We investigate the applicability
and efficacy of auditory masking in devising a robust front end
for noisy features. This is achieved by introducing a masking
factor into the Vector Taylor Series (VTS) equations. The resultant
first order VTS approximation is used to compensate the parameters
of a clean speech model and a Minimum Mean Square
Error (MMSE) estimate is used to estimate the clean speech
Paper17_BD.pdf
- Categories:
3 Views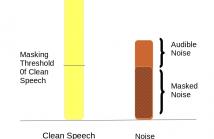
- Read more about Vector Taylor Series Expansion with Auditory Masking for Noise Robust Speech Recognition
- Log in to post comments
In this paper, we address the problem of speech recognition in
the presence of additive noise. We investigate the applicability
and efficacy of auditory masking in devising a robust front end
for noisy features. This is achieved by introducing a masking
factor into the Vector Taylor Series (VTS) equations. The resultant
first order VTS approximation is used to compensate the parameters
of a clean speech model and a Minimum Mean Square
Error (MMSE) estimate is used to estimate the clean speech
Paper17_BD.pdf
- Categories:
4 Views- Read more about Towards Automatic Assessment of Aphasia Speech Using Automatic Speech Recognition Techniques
- Log in to post comments
Aphasia is a type of acquired language impairment caused by brain injury. This paper presents an automatic speech recog- nition (ASR) based approach to objective assessment of apha- sia patients. A dedicated ASR system is developed to facilitate acoustical and linguistic analysis of Cantonese aphasia speech. The acoustic models and the language models are trained with domain- and style-matched speech data from unimpaired con- trol speakers. The speech recognition performance of this sys- tem is evaluated on natural oral discourses from patients with various types of aphasia.
- Categories:
9 Views- Read more about Mismatched Training Data Enhancement for Automatic Recognition of Children’s Speech using DNN-HMM
- Log in to post comments
The increasing profusion of commercial automatic speech recognition technology applications has been driven by big-data techniques, making use of high quality labelled speech datasets. Children’s speech displays greater time and frequency domain variability than typical adult speech, lacks the depth and breadth of training material, and presents difficulties relating to capture quality. All of these factors act to reduce the achievable performance of systems that recognise children’s speech.
- Categories:
3 Views