- Read more about BLOCK-SPARSE ADVERSARIAL ATTACK TO FOOL TRANSFORMER-BASED TEXT CLASSIFIERS
- Log in to post comments
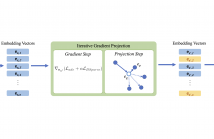
Recently, it has been shown that, in spite of the significant performance of deep neural networks in different fields, those are vulnerable to adversarial examples. In this paper, we propose a gradient-based adversarial attack against transformer-based text classifiers. The adversarial perturbation in our method is imposed to be block-sparse so that the resultant adversarial example differs from the original sentence in only a few words. Due to the discrete nature of textual data, we perform gradient projection to find the minimizer of our proposed optimization problem.
- Categories:
 40 Views
40 Views
- Read more about Defending DNN Adversarial Attacks with Pruning and Logits Augmentation
- Log in to post comments
Deep neural networks (DNNs) have been shown to be powerful models and perform extremely well on many complicated artificial intelligent tasks. However, recent research found that these powerful models are vulnerable to adversarial attacks, i.e., intentionally added imperceptible perturbations to DNN inputs can easily mislead the DNNs with extremely high confidence. In this work, we enhance the robustness of DNNs under adversarial attacks by using pruning method and logits augmentation, we achieve both effective defense against adversarial examples and DNN model compression.
- Categories:
28 Views