IEEE ICASSP 2024 - IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The IEEE ICASSP 2024 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit the website.
- Read more about ENHANCING NOISY LABEL LEARNING VIA UNSUPERVISED CONTRASTIVE LOSS WITH LABEL CORRECTION BASED ON PRIOR KNOWLEDGE
- Log in to post comments
To alleviate the negative impacts of noisy labels, most of the noisy label learning (NLL) methods dynamically divide the training data into two types, “clean samples” and “noisy samples”, in the training process. However, the conventional selection of clean samples heavily depends on the features learned in the early stages of training, making it difficult to guarantee the cleanliness of the selected samples in scenarios where the noise ratio is high.
- Categories:
 81 Views
81 Views- Read more about Detecting Check-Worthy Claims in Political Debates, Speeches, and Interviews Using Audio Data - Poster
- Log in to post comments
Developing tools to automatically detect check-worthy claims in political debates and speeches can greatly help moderators of debates, journalists, and fact-checkers. While previous work on this problem has focused exclusively on the text modality, here we explore the utility of the audio modality as an additional input. We create a new multimodal dataset (text and audio in English) containing 48 hours of speech from past political debates in the USA.
- Categories:
36 Views- Read more about Detecting Check-Worthy Claims in Political Debates, Speeches, and Interviews Using Audio Data - Presentation
- Log in to post comments
Developing tools to automatically detect check-worthy claims in political debates and speeches can greatly help moderators of debates, journalists, and fact-checkers. While previous work on this problem has focused exclusively on the text modality, here we explore the utility of the audio modality as an additional input. We create a new multimodal dataset (text and audio in English) containing 48 hours of speech from past political debates in the USA.
- Categories:
36 Views- Read more about TOWARDS MULTI-DOMAIN FACE LANDMARK DETECTION WITH SYNTHETIC DATA FROM DIFFUSION MODEL
- Log in to post comments
Recently, deep learning-based facial landmark detection for in-the-wild faces has achieved significant improvement. However, there are still challenges in face landmark detection in other domains (\eg{} cartoon, caricature, etc). This is due to the scarcity of extensively annotated training data. To tackle this concern, we design a two-stage training approach that effectively leverages limited datasets and the pre-trained diffusion model to obtain aligned pairs of landmarks and face in multiple domains.
- Categories:
29 Views- Read more about [poster] Improving Design of Input Condition Invariant Speech Enhancement
- Log in to post comments
Building a single universal speech enhancement (SE) system that can handle arbitrary input is a demanded but underexplored research topic. Towards this ultimate goal, one direction is to build a single model that handles diverse audio duration, sampling frequencies, and microphone variations in noisy and reverberant scenarios, which we define here as “input condition invariant SE”. Such a model was recently proposed showing promising performance; however, its multi-channel performance degraded severely in real conditions.
- Categories:
47 Views- Read more about [slides] Generation-Based Target Speech Extraction with Speech Discretization and Vocoder
- Log in to post comments
Target speech extraction (TSE) is a task aiming at isolating the speech of a specific target speaker from an audio mixture, with the help of an auxiliary recording of that target speaker. Most existing TSE methods employ discrimination-based models to estimate the target speaker’s proportion in the mixture, but they often fail to compensate for the missing or highly corrupted frequency components in the speech signal. In contrast, the generation-based methods can naturally handle such scenarios via speech resynthesis.
- Categories:
48 Views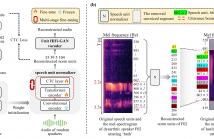
- Read more about UNIT-DSR: DYSARTHRIC SPEECH RECONSTRUCTION SYSTEM USING SPEECH UNIT NORMALIZATION
- 1 comment
- Log in to post comments
Dysarthric speech reconstruction (DSR) systems aim to automatically convert dysarthric speech into normal-sounding speech. The technology eases communication with speakers affected by the neuromotor disorder and enhances their social inclusion.
- Categories:
85 Views
- Read more about Poster
- Log in to post comments
This paper introduces BWSNet, a model that can be trained from raw human judgements obtained through a Best-Worst scaling (BWS) experiment. It maps sound samples into an embedded space that represents the perception of a studied attribute. To this end, we propose a set of cost functions and constraints, interpreting trial-wise ordinal relations as distance comparisons in a metric learning task. We tested our proposal on data from two BWS studies investigating the perception of speech social attitudes and timbral qualities.
- Categories:
75 Views- Read more about ENHANCING MULTILINGUAL TTS WITH VOICE CONVERSION BASED DATA AUGMENTATION AND POSTERIOR EMBEDDING
- Log in to post comments
This paper proposes a multilingual, multi-speaker (MM) TTS system by using a voice conversion (VC)-based data augmentation method. Creating an MM-TTS model is challenging, owing to the difficulties of collecting polyglot data from multiple speakers. To address this problem, we adopt a cross-lingual, multi-speaker VC model trained with multiple speakers’ monolingual databases. As this model effectively transfers acoustic attributes while retaining the content information, it is possible to generate each speaker’s polyglot corpora.
- Categories:
49 Views- Read more about A SOUND APPROACH: Using Large Language Models to generate audio descriptions for egocentric text-audio retrieval - Poster
- Log in to post comments
Video databases from the internet are a valuable source of text-audio retrieval datasets. However, given that sound and vision streams represent different "views" of the data, treating visual descriptions as audio descriptions is far from optimal. Even if audio class labels are present, they commonly are not very detailed, making them unsuited for text-audio retrieval. To exploit relevant audio information from video-text datasets, we introduce a methodology for generating audio-centric descriptions using Large Language Models (LLMs).
- Categories:
38 Views