Documents
Poster
Adversarial Advantage Actor-Critic Model for Task-Completion Dialogue Policy Learning
- Citation Author(s):
- Submitted by:
- Yun-Nung Chen
- Last updated:
- 22 April 2018 - 12:00pm
- Document Type:
- Poster
- Document Year:
- 2018
- Event:
- Presenters:
- Yun-Nung Chen
- Paper Code:
- HLT-P2.4
- Categories:
- Log in to post comments
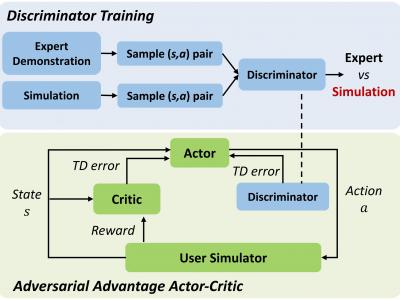
This paper presents a new method --- adversarial advantage actor-critic (Adversarial A2C), which significantly improves the efficiency of dialogue policy learning in task-completion dialogue systems. Inspired by generative adversarial networks (GAN), we train a discriminator to differentiate responses/actions generated by dialogue agents from responses/actions by experts. Then, we incorporate the discriminator as another critic into the advantage actor-critic (A2C) framework, to encourage the dialogue agent to explore state-action within the regions where the agent takes actions similar to those of the experts. Experimental results in a movie-ticket booking domain show that the proposed Adversarial A2C can accelerate policy exploration efficiently.

