Documents
Poster
Domain and speaker adaptation for Cortana Speech Recognition
- Citation Author(s):
- Submitted by:
- Yong Zhao
- Last updated:
- 12 April 2018 - 7:35pm
- Document Type:
- Poster
- Document Year:
- 2018
- Event:
- Presenters:
- Yong Zhao
- Paper Code:
- SP-P20.9
- Categories:
- Log in to post comments
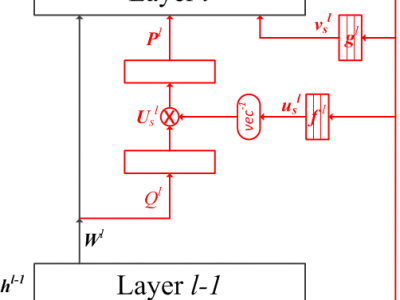
Voice assistant represents one of the most popular and important scenarios for speech recognition. In this paper, we propose two adaptation approaches to customize a multi-style well-trained acoustic model towards its subsidiary domain of Cortana assistant. First, we present anchor-based speaker adaptation by extracting the speaker information, i-vector or d-vector embeddings, from the anchor segments of `Hey Cortana'. The anchor embeddings are mapped to layer-wise parameters to control the transformations of both weight matrices and biases of multiple layers. Second, we directly update the existing model parameters for domain adaptation. We demonstrate that prior distribution should be updated along with the network adaptation to compensate the label bias from the development data. Updating the priors may have a significant impact when the target domain features high occurrence of anchor words. Experiments on Hey Cortana desktop test set show that both approaches improve the recognition accuracy significantly. The anchor-based adaptation using the anchor d-vector and the prior interpolation achieves 32% relative reduction in WER over the generic model.

