Documents
Poster
Implementation of Efficient, Low Power Deep Neural Networks on Next-Generation Intel Client Platforms
- Citation Author(s):
- Submitted by:
- Michael Deisher
- Last updated:
- 12 April 2017 - 10:44am
- Document Type:
- Poster
- Document Year:
- 2017
- Event:
- Presenters:
- Mike Deisher
- Paper Code:
- ICASSP1701 4
- Categories:
- Log in to post comments
ICASSP 2017 Demonstration
In recent years many signal processing applications involving classification, detection, and inference have enjoyed substantial accuracy improvements due to advances in deep learning. At the same time, the “Internet of Things” has become an important class of devices. Although the paradigm of local sensing and remote inference has been very successful (e.g., Apple Siri, Google Now, Microsoft Cortana, Amazon Alexa, and others) there exist many valuable applications where sensing duration is very long, the cost of communication is high, and scaling to millions or billions of devices is not practical. In such cases, local inference “at the edge” is attractive provided it can be done without compromising accuracy and within the thermal envelope and expected battery life of the edge device.
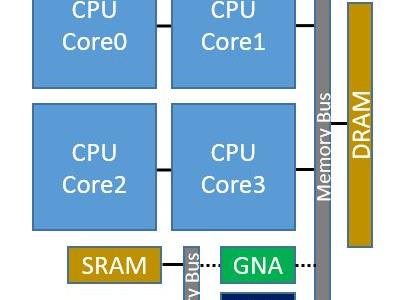
This demonstration presents a very low power neural network co-processor called GNA (Gaussian mixture model and neural network accelerator) that is capable of continuous inference on local battery powered devices. A pre-production reference platform is demonstrated. Continuous acoustic model likelihood scoring is shown using models trained with the open source Kaldi framework. Acoustic likelihoods are presented in a real-time spectrogram-like display (likelihood-o-gram). First, a speed test is shown pitting the application processor (e.g., CPU) against the neural network co-processor. The application processor and accelerator block are used to score acoustic feature vector inputs as fast as possible while the scrolling output is displayed. A stopwatch timer is shown for each as a way of comparing performance. A resource monitor showing application processor utilization is also shown. Performance for deep networks of fully connected layers and long short term memory (LSTM) layers is demonstrated. Second, a real-time large vocabulary continuous speech recognition (LVCSR) system is shown as live audio input from a TED Talk video plays into the microphone input. Application processor utilization is shown while acoustic likelihood scoring is moved from the CPU to the co-processor and back, demonstrating significantly lower CPU load when the co-processor is used. A brief presentation of the programming model and best known methods is given. Development flow using the Intel® Deep Learning SDK is shown.
The value of this demonstration to participants is several-fold. It introduces researchers and practitioners to early technology showing that commodity hardware for remote, highly accurate, low power, continuous inference is around the corner. It allows them to familiarize themselves with the technology, tools, and infrastructure in advance. Also, real-time likelihood-o-gram is introduced as a way to visualize neural network performance on live audio. Techniques for rapid prototyping of efficient neural network based applications are discussed giving plenty of opportunity for brainstorming and sharing of ideas. Participants gain knowledge that can be applied across future Intel embedded, mobile client, and PC/workstation platforms.

