
ICASSP is the world's largest and most comprehensive technical conference on signal processing and its applications. It provides a fantastic networking opportunity for like-minded professionals from around the world. ICASSP 2017 conference will feature world-class presentations by internationally renowned speakers and cutting-edge session topics. Visit ICASSP 2017
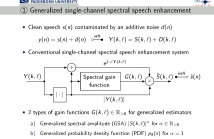
- Read more about A GENERALIZED LOG-SPECTRAL AMPLITUDE ESTIMATOR FOR SINGLE-CHANNEL SPEECH ENHANCEMENT
- Log in to post comments
The benefits of both a logarithmic spectral amplitude (LSA) estimation and a modeling in a generalized spectral domain (where short-time amplitudes are raised to a generalized power exponent, not restricted to magnitude or power spectrum) are combined in this contribution to achieve a better tradeoff between speech quality and noise suppression in single-channel speech enhancement. A novel gain function is derived to enhance the logarithmic generalized spectral amplitudes of noisy speech.
- Categories:
 25 Views
25 Views- Read more about Phase-dependent anisotropic Gaussian model for audio source separation
- Log in to post comments
Phase reconstruction of complex components in the time-frequency domain is a challenging but necessary task for audio source separation. While traditional approaches do not exploit phase constraints that originate from signal modeling, some prior information about the phase can be obtained from sinusoidal modeling. In this paper, we introduce a probabilistic mixture model which allows us to incorporate such phase priors within a source separation framework.
2017_icassp.pdf
- Categories:
25 Views
- Read more about A study of speaker verification performance with expressive speech
- Log in to post comments
Expressive speech introduces variations in the acoustic features affecting the performance of speech technology such as speaker verification systems. It is important to identify the range of emotions for which we can reliably estimate speaker verification tasks. This paper studies the performance of a speaker verification system as a function of emotions. Instead of categorical classes such as happiness or anger, which have important intra-class variability, we use the continuous attributes arousal, valence, and dominance which facili- tate the analysis.
- Categories:
92 Views- Read more about Ensemble feature selection for domain adaptation in speech emotion recognition
- Log in to post comments
When emotion recognition systems are used in new domains, the classification performance usually drops due to mismatches between training and testing conditions. Annotations of new data in the new domain is expensive and time demanding. Therefore, it is important to design strategies that efficiently use limited amount of new data to improve the robustness of the classification system. The use of ensembles is an attractive solution, since they can be built to perform well across different mismatches. The key challenge is to create ensembles that are diverse.
- Categories:
18 Views- Read more about Incremental adaptation using active learning for acoustic emotion recognition
- Log in to post comments
The performance of speech emotion classifiers greatly degrade when the training conditions do not match the testing conditions. This problem is observed in cross-corpora evaluations, even when the corpora are similar. The lack of generalization is particularly problematic when the emotion classifiers are used in real applications. This study addresses this problem by combining active learning (AL) and supervised domain adaptation (DA) using an elegant approach for support vector machine (SVM).
Poster-CB.pdf
- Categories:
20 Views- Read more about HIGH PERFORMANCE SUPERVISED TIME-DELAY ESTIMATION USING NEURAL NETWORKS
- Log in to post comments
Time-delay estimation is an essential building block of many signal processing applications. This paper follows up on earlier work for acoustic source localization and time delay estimation using pattern recognition techniques; it presents high performance results obtained with supervised training of neural networks which challenge the state of the art and compares its performance to that of well-known methods such as the Generalized Cross-Correlation or Adaptive Eigenvalue Decomposition.
- Categories:
110 Views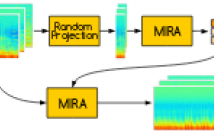
Live concert recordings consist in long multitrack audio samples with significant interferences between channels. For audio engineering purposes, it is desirable to attenuate those interferences. Recently, we proposed an algorithm to this end based on Non-negative Matrix Factorization, that iteratively estimate the clean power spectral densities of the sources and the strength of each in each microphone signal, encoded in an interference matrix. Although it behaves well, this method is too demanding computationally for full-length concerts lasting more than one hour.
output.pdf
- Categories:
16 Views- Read more about END-TO-END JOINT LEARNING OF NATURAL LANGUAGE UNDERSTANDING AND DIALOGUE MANAGER
- Log in to post comments
- Categories:
30 Views- Read more about Virtual Reality Content Streaming: Viewport-Dependent Projection and Tile-based Techniques
- Log in to post comments
- Categories:
43 Views- Read more about ARTIFICIAL BANDWIDTH EXTENSION USING THE CONSTANT Q TRANSFORM
- Log in to post comments
- Categories:
13 Views