Documents
Presentation Slides
Improving Audio Captioning Models with Fine-grained Audio Features, Text Embedding Supervision, and LLM Mix-up Augmentation
- Citation Author(s):
- Submitted by:
- Shih-Lun Wu
- Last updated:
- 15 April 2024 - 1:19am
- Document Type:
- Presentation Slides
- Categories:
- Log in to post comments
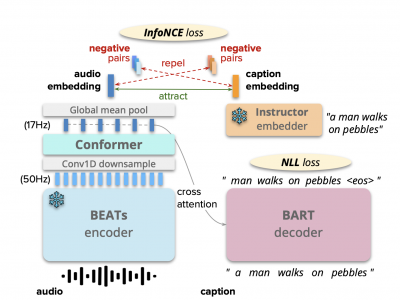
Automated audio captioning (AAC) aims to generate informative descriptions for various sounds from nature and/or human activities. In recent years, AAC has quickly attracted research interest, with state-of-the-art systems now relying on a sequence-to-sequence (seq2seq) backbone powered by strong models such as Transformers. Following the macro-trend of applied machine learning research, in this work, we strive to improve the performance of seq2seq AAC models by extensively leveraging pretrained models and large language models (LLMs). Specifically, we utilize BEATs to extract fine-grained audio features. Then, we employ Instructor LLM to fetch text embeddings of captions, and infuse their language-modality knowledge into BEATs audio features via an auxiliary InfoNCE loss function. Moreover, we propose a novel data augmentation method that uses ChatGPT to produce caption mix-ups (i.e., grammatical and compact combinations of two captions) which, together with the corresponding audio mixtures, increase not only the amount but also the complexity and diversity of training data. During inference, we propose to employ nucleus sampling and a hybrid reranking algorithm, which has not been explored in AAC research. Combining our efforts, our model achieves a new state-of-the-art 32.6 SPIDEr-FL score on the Clotho evaluation split, and wins the 2023 DCASE AAC challenge.

