- Transducers
- Spatial and Multichannel Audio
- Source Separation and Signal Enhancement
- Room Acoustics and Acoustic System Modeling
- Network Audio
- Audio for Multimedia
- Audio Processing Systems
- Audio Coding
- Audio Analysis and Synthesis
- Active Noise Control
- Auditory Modeling and Hearing Aids
- Bioacoustics and Medical Acoustics
- Music Signal Processing
- Loudspeaker and Microphone Array Signal Processing
- Echo Cancellation
- Content-Based Audio Processing
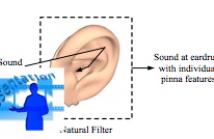
- Read more about Natural Sound Rendering for Headphones: Integration of signal processing techniques (slides)
- Log in to post comments
With the strong growth of assistive and personal listening devices, natural sound rendering over headphones is becoming a necessity for prolonged listening in multimedia and virtual reality applications. The aim of natural sound rendering is to naturally recreate the sound scenes with the spatial and timbral quality as natural as possible, so as to achieve a truly immersive listening experience. However, rendering natural sound over headphones encounters many challenges. This tutorial article presents signal processing techniques to tackle these challenges to assist human listening.
- Categories:
 103 Views
103 Views- Read more about [poster] Improving Design of Input Condition Invariant Speech Enhancement
- Log in to post comments
Building a single universal speech enhancement (SE) system that can handle arbitrary input is a demanded but underexplored research topic. Towards this ultimate goal, one direction is to build a single model that handles diverse audio duration, sampling frequencies, and microphone variations in noisy and reverberant scenarios, which we define here as “input condition invariant SE”. Such a model was recently proposed showing promising performance; however, its multi-channel performance degraded severely in real conditions.
- Categories:
47 Views- Read more about [slides] Generation-Based Target Speech Extraction with Speech Discretization and Vocoder
- Log in to post comments
Target speech extraction (TSE) is a task aiming at isolating the speech of a specific target speaker from an audio mixture, with the help of an auxiliary recording of that target speaker. Most existing TSE methods employ discrimination-based models to estimate the target speaker’s proportion in the mixture, but they often fail to compensate for the missing or highly corrupted frequency components in the speech signal. In contrast, the generation-based methods can naturally handle such scenarios via speech resynthesis.
- Categories:
53 Views
- Read more about Poster
- Log in to post comments
This paper introduces BWSNet, a model that can be trained from raw human judgements obtained through a Best-Worst scaling (BWS) experiment. It maps sound samples into an embedded space that represents the perception of a studied attribute. To this end, we propose a set of cost functions and constraints, interpreting trial-wise ordinal relations as distance comparisons in a metric learning task. We tested our proposal on data from two BWS studies investigating the perception of speech social attitudes and timbral qualities.
- Categories:
80 Views- Read more about ENHANCING MULTILINGUAL TTS WITH VOICE CONVERSION BASED DATA AUGMENTATION AND POSTERIOR EMBEDDING
- Log in to post comments
This paper proposes a multilingual, multi-speaker (MM) TTS system by using a voice conversion (VC)-based data augmentation method. Creating an MM-TTS model is challenging, owing to the difficulties of collecting polyglot data from multiple speakers. To address this problem, we adopt a cross-lingual, multi-speaker VC model trained with multiple speakers’ monolingual databases. As this model effectively transfers acoustic attributes while retaining the content information, it is possible to generate each speaker’s polyglot corpora.
- Categories:
50 ViewsWe propose a decoder-only language model, VoxtLM, that can perform four tasks: speech recognition, speech synthesis, text generation, and speech continuation. VoxtLM integrates text vocabulary with discrete speech tokens from self-supervised speech features and uses special tokens to enable multitask learning. Compared to a single-task model, VoxtLM exhibits a significant improvement in speech synthesis, with improvements in both speech intelligibility from 28.9 to 5.6 and objective quality from 2.68 to 3.90.
- Categories:
21 Views- Read more about Can Large-scale Vocoded Spoofed Data Improve Speech Spoofing Countermeasure with a Self-supervised Front End?
- 1 comment
- Log in to post comments
A speech spoofing countermeasure (CM) that discriminates between unseen spoofed and bona fide data requires diverse training data. While many datasets use spoofed data generated by speech synthesis systems, it was recently found that data vocoded by neural vocoders were also effective as the spoofed training data. Since many neural vocoders are fast in building and generation, this study used multiple neural vocoders and created more than 9,000 hours of vocoded data on the basis of the VoxCeleb2 corpus.
- Categories:
39 Views- Read more about TIA: A TEACHING INTONATION ASSESSMENT DATASET IN REAL TEACHING SITUATIONS
- Log in to post comments
Intonation is one of the important factors affecting the teaching language arts, so it is an urgent problem to be addressed by evaluating the teachers’ intonation through artificial intelligence technology. However, the lack of an intonation assessment dataset has hindered the development of the field. To this end, this paper constructs a Teaching Intonation Assessment (TIA) dataset for the first time in real teaching situations. This dataset covers 9 disciplines, 396 teachers, total of 11,444 utterance samples with a length of 15 seconds.
- Categories:
46 Views- Read more about SALM: Speech-augmented Language Model with In-context Learning for Speech Recognition and Translation
- 1 comment
- Log in to post comments
We present a novel Speech Augmented Language Model (SALM) with multitask and in-context learning capabilities. SALM comprises a frozen text LLM, a audio encoder, a modality adapter module, and LoRA layers to accommodate speech input and associated task instructions. The unified SALM not only achieves performance on par with task-specific Conformer baselines for Automatic Speech Recognition (ASR) and Speech Translation (AST), but also exhibits zero-shot in-context learning capabilities, demonstrated through keyword-boosting task for ASR and AST.
- Categories:
59 Views- Read more about SALM: Speech-augmented Language Model with In-context Learning for Speech Recognition and Translation
- Log in to post comments
We present a novel Speech Augmented Language Model (SALM) with multitask and in-context learning capabilities. SALM comprises a frozen text LLM, a audio encoder, a modality adapter module, and LoRA layers to accommodate speech input and associated task instructions. The unified SALM not only achieves performance on par with task-specific Conformer baselines for Automatic Speech Recognition (ASR) and Speech Translation (AST), but also exhibits zero-shot in-context learning capabilities, demonstrated through keyword-boosting task for ASR and AST.
- Categories:
27 Views