Documents
Poster
MULTI-VIEW VISUAL SPEECH RECOGNITION BASED ON MULTI TASK LEARNING
- Citation Author(s):
- Submitted by:
- HouJeung Han
- Last updated:
- 15 September 2017 - 3:48am
- Document Type:
- Poster
- Document Year:
- 2017
- Event:
- Presenters:
- HouJeung Han
- Paper Code:
- ICIP1701
- Categories:
- Log in to post comments
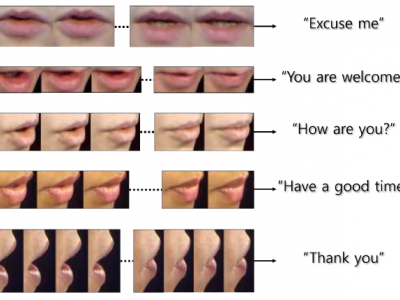
Visual speech recognition (VSR), also known as lip reading is a task that recognizes words or phrases using video clips of lip movement. Traditional VSR methods are limited in that they are based mostly on VSR of frontal-view facial movement. However, for practical application, VSR should include lip movement from all angles. In this paper, we propose a pose-invariant network which can recognize words spoken from any arbitrary view input. The architecture combines convolutional neural network (CNN) with bidirectional long short-term memory (LSTM) and is trained in a multi-task manner such that the pose and the word spoken are jointly classified. Here, pose classification is considered as an auxiliary task. To comparatively evaluate the performance of the proposed multi-task learning method, the OuluVS2 benchmark dataset is used. The experimental results demonstrate that the deep model learned based on the proposed multi-task learning method achieved much better performance than models produced by previous single-view VSR methods and multi-view lip reading methods. This deep model achieved recognition performance of 95.0% accuracy on the OuluVS2 dataset.

