Documents
Poster
Study of dense network approaches for speech emotion recognition
- Citation Author(s):
- Submitted by:
- Carlos Busso
- Last updated:
- 20 May 2020 - 9:56am
- Document Type:
- Poster
- Document Year:
- 2018
- Event:
- Presenters:
- Carlos Busso
- Categories:
- Log in to post comments
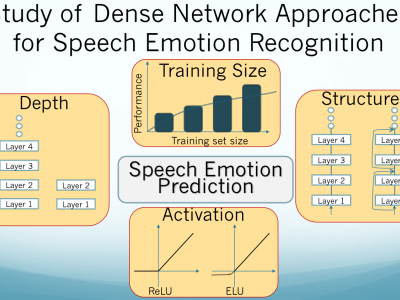
Deep neural networks have been proven to be very effective in various classification problems and show great promise for emotion recognition from speech. Studies have proposed various architectures that further improve the performance of emotion recognition systems. However, there are still various open questions regarding the best approach to building a speech emotion recognition system. Would the system’s performance improve if we have more labeled data? How much do we benefit from data augmentation? What activation and regularization schemes are more beneficial? How does the depth of the network affect the performance? We are collecting the MSP-Podcast corpus, a large dataset with over 30 hours of data, which provides an ideal resource to address these questions. This study explores various dense architectures to predict arousal, valence and dominance scores. We investigate varying the training set size, width, and depth of the network, as well as the activation functions used during training. We also study the effect of data augmentation on the network’s performance. We find that bigger training set im- proves the performance. Batch normalization is crucial to achieving a good performance for deeper networks. We do not observe signif- icant differences in the performance in residual networks compared to dense networks.

