Documents
Presentation Slides
Presentation Slides
Vector Taylor Series Expansion with Auditory Masking for Noise Robust Speech Recognition
- Citation Author(s):
- Submitted by:
- Biswajit Das
- Last updated:
- 14 October 2016 - 8:15am
- Document Type:
- Presentation Slides
- Document Year:
- 2016
- Event:
- Presenters:
- Biswajit Das
- Paper Code:
- ISCSLP1601
- Categories:
- Log in to post comments
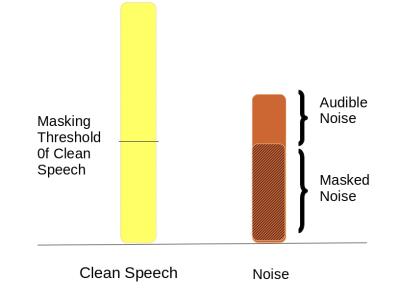
In this paper, we address the problem of speech recognition in
the presence of additive noise. We investigate the applicability
and efficacy of auditory masking in devising a robust front end
for noisy features. This is achieved by introducing a masking
factor into the Vector Taylor Series (VTS) equations. The resultant
first order VTS approximation is used to compensate the parameters
of a clean speech model and a Minimum Mean Square
Error (MMSE) estimate is used to estimate the clean speech
features. The proposed algorithms are validated through experiments
on a noise corrupted TIMIT speech recognition database.
We show significant performance gain for the proposed method
as compared to the traditional VTS algorithm.

