- Read more about A Robust Quantile Huber Loss with Interpretable Parameter Adjustment in Distributional Reinforcement Learning
- Log in to post comments
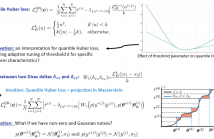
Distributional Reinforcement Learning (RL) estimates return distribution mainly by learning quantile values via minimizing the quantile Huber loss function, entailing a threshold parameter often selected heuristically or via hyperparameter search, which may not generalize well and can be suboptimal. This paper introduces a generalized quantile Huber loss function derived from Wasserstein distance (WD) calculation between Gaussian distributions, capturing noise in predicted (current) and target (Bellmanupdated) quantile values.
- Categories:
 37 Views
37 Views