- Read more about ICASSP2024-Paper ID 3371-IVMSP-L2.4: VT-REID: LEARNING DISCRIMINATIVE VISUAL-TEXT REPRESENTATION FOR POLYP RE-IDENTIFICATION
- Log in to post comments
Presention Slides in ICASSP2024 for IVMSP-L2.4: VT-REID: LEARNING DISCRIMINATIVE VISUAL-TEXT REPRESENTATION FOR POLYP RE-IDENTIFICATION
- Categories:
 18 Views
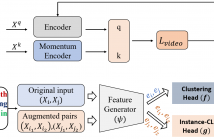
18 Views- Read more about PART REPRESENTATION LEARNING WITH TEACHER-STUDENT DECODER FOR OCCLUDED PERSON RE-IDENTIFICATION
- Log in to post comments
Occluded person re-identification (ReID) is a very challenging task due to the occlusion disturbance and incomplete target information. Leveraging external cues such as human pose or parsing to locate and align part features has been proven to be very effective in occluded person ReID. Meanwhile, recent Transformer structures have a strong ability of long-range modeling. Considering the above facts, we propose a Teacher-Student Decoder (TSD) framework for occluded person ReID, which utilizes the Transformer decoder with the help of human parsing.
- Categories:
29 Views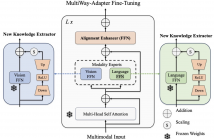
- Read more about MultiWay-Adapter: Adapting Multimodal Large Language Models for scalable image-text retrieval
- Log in to post comments
As Multimodal Large Language Models (MLLMs) grow in size, adapting them to specialized tasks becomes increasingly challenging due to high computational and memory demands. While efficient adaptation methods exist, in practice they suffer from shallow inter-modal alignment, which severely hurts model effectiveness. To tackle these challenges, we introduce the MultiWay-Adapter (MWA), which deepens inter-modal alignment, enabling high transferability with minimal tuning effort.
- Categories:
5 Views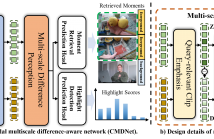
- Read more about Cross-modal Multiscale Difference-aware Network for Joint Moment Retrieval and Highlight Detection
- Log in to post comments
Since the goals of both Moment Retrieval (MR) and Highlight Detection (HD) are to quickly obtain the required content from the video according to user needs, several works have attempted to take advantage of the commonality between both tasks to design transformer-based networks for joint MR and HD. Although these methods achieve impressive performance, they still face some problems: \textbf{a)} Semantic gaps across different modalities. \textbf{b)} Various durations of different query-relevant moments and highlights. \textbf{c)} Smooth transitions among diverse events.
- Categories:
10 Views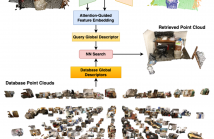
- Read more about AEGIS-Net: Attention-Guided Multi-Level Feature Aggregation for Indoor Place Recognition
- Log in to post comments
We present AEGIS-Net, a novel indoor place recognition model that takes in RGB point clouds and generates global place descriptors by aggregating lower-level color, geometry features and higher-level implicit semantic features. However, rather than simple feature concatenation, self-attention modules are employed to select the most important local features that best describe an indoor place. Our AEGIS-Net is made of a semantic encoder, a semantic decoder and an attention-guided feature embedding.
Poster.pdf
- Categories:
7 Views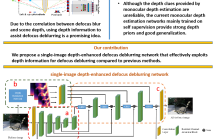
- Read more about EFFICIENT FUSION OF DEPTH INFORMATION FOR DEFOCUS DEBLURRING
- 1 comment
- Log in to post comments
Defocus deblurring is a classic problem in image restoration tasks. The formation of its defocus blur is related to depth. Recently, the use of dual-pixel sensor designed according to depth-disparity characteristics has brought great improvements to the defocus deblurring task. However, the difficulty of real-time acquisition of dual-pixel images brings difficulties to algorithm deployment. This inspires us to remove defocus blur by single image with depth information.
- Categories:
94 Views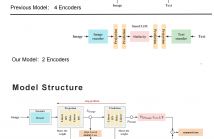
- Read more about SiamCLIM: Text-Based Pedestrian Search via Multi-modal Siamese Contrastive Learning
- Log in to post comments
Text-based pedestrian search (TBPS) aims at retrieving target persons from the image gallery through descriptive text queries. Despite remarkable progress in recent state-of-the-art approaches, previous works still struggle to efficiently extract discriminative features from multi-modal data. To address the problem of cross-modal fine-grained text-to-image, we proposed a novel Siamese Contrastive Language-Image Model (SiamCLIM).
- Categories:
14 Views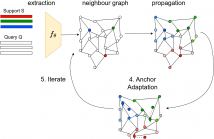
- Read more about Adaptive Anchor Label Propagation for Transductive Few-Shot Learning
- Log in to post comments
Few-shot learning addresses the issue of classifying images using limited labeled data. Exploiting unlabeled data through the use of transductive inference methods such as label propagation has been shown to improve the performance of few-shot learning significantly. Label propagation infers pseudo-labels for unlabeled data by utilizing a constructed graph that exploits the underlying manifold structure of the data.
- Categories:
25 Views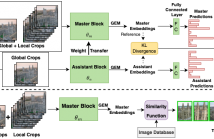
- Read more about MABNet: Master Assistant Buddy Network with Hybrid Learning for Image Retrieval
- Log in to post comments
Image retrieval has garnered a growing interest in recent times. The current approaches are either supervised or self-supervised. These methods do not exploit the benefits of hybrid learning using both supervision and self-supervision. We present a novel Master Assistant Buddy Network (MABNet) for image retrieval which incorporates both the learning mechanisms. MABNet consists of master and assistant block, both learning independently through supervision and collectively via self-supervision.
- Categories:
8 Views
- Read more about Invert-and-project (IVP)-A Lossless Compression Method of Multi-scale JPEG Images via DCT Coefficients Prediction
- Log in to post comments
JPEG is a versatile and widely used format for images. Based an elegant design that enables the joint works of basis transformation (gross-scale decorrelation) and entropy coding (fine-scale coding), the resulting JPEG image can maintain virtually all visible features of an image while reducing its size to one tens of the original raw data.
- Categories:
32 Views