
- Read more about An Analysis of Speech Enhancement and Recognition Losses in Limited Resources Multi-Talker Single Channel Audio-Visual ASR
- Log in to post comments
In this paper, we analyzed how audio-visual speech enhancement can help to perform the ASR task in a cocktail party scenario. Therefore we considered two simple end-to-end LSTM-based models that perform single-channel audiovisual speech enhancement and phone recognition respectively. Then, we studied how the two models interact, and how to train them jointly affects the final result.We analyzed different training strategies that reveal some interesting and unexpected behaviors.
- Categories:
 53 Views
53 Views
- Read more about Small energy masking for improved neural network training for end-to-end speech recognition
- Log in to post comments
In this paper, we present a Small Energy Masking (SEM) algorithm, which masks inputs having values below a certain threshold. More specifically, a time-frequency bin is masked if the filterbank energy in this bin is less than a certain energy threshold. A uniform distribution is employed to randomly generate the ratio of this energy threshold to the peak filterbank energy of each utterance in decibels. The unmasked feature elements are scaled so that the total sum of the feature values remain the same through this masking procedure.
- Categories:
33 Views
- Read more about Learning Discriminative Features in Sequence Training without Requiring Framewise Labelled Data
- Log in to post comments
Slides.pdf
- Categories:
34 Views
- Read more about Conditional Teacher-Student Learning
- Log in to post comments
The teacher-student (T/S) learning has been shown to be effective for a variety of problems such as domain adaptation and model compression. One shortcoming of the T/S learning is that a teacher model, not always perfect, sporadically produces wrong guidance in form of posterior probabilities that misleads the student model towards a suboptimal performance.
- Categories:
50 Views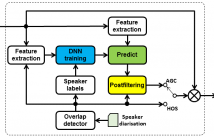
The CHiME-5 speech separation and recognition challenge was recently shown to pose a difficult task for the current automatic speech recognition systems.
Speaker overlap was one of the main difficulties of the challenge. The presence of noise, reverberation and the moving speakers have made the traditional source separation methods ineffective in improving the recognition accuracy.
In this paper we have explored several enhancement strategies aimed to reduce the effect of speaker overlap for CHiME-5 without performing source separation.
- Categories:
31 Views
The performance of Automatic Speech Recognition (ASR) systems is often measured using Word Error Rates (WER) which requires time-consuming and expensive manually transcribed data. In this paper, we use state-of-the-art ASR systems based on Deep Neural Networks (DNN) and propose a novel framework which uses ``Dropout'' at the test time to model uncertainty in prediction hypotheses. We systematically exploit this uncertainty to estimate WER without the need for explicit transcriptions.
- Categories:
55 Views
- Read more about MULTI-GEOMETRY SPATIAL ACOUSTIC MODELING FOR DISTANT SPEECH RECOGNITION
- Log in to post comments
The use of spatial information with multiple microphones can improve far-field automatic speech recognition (ASR) accuracy. However, conventional microphone array techniques degrade speech enhancement performance when there is an array geometry mismatch between design and test conditions. Moreover, such speech enhancement techniques do not always yield ASR accuracy improvement due to the difference between speech enhancement and ASR optimization objectives.
- Categories:
16 Views
- Read more about FREQUENCY DOMAIN MULTI-CHANNEL ACOUSTIC MODELING FOR DISTANT SPEECH RECOGNITION
- Log in to post comments
Conventional far-field automatic speech recognition (ASR) systems typically employ microphone array techniques for speech enhancement in order to improve robustness against noise or reverberation. However, such speech enhancement techniques do not always yield ASR accuracy improvement because the optimization criterion for speech enhancement is not directly relevant to the ASR objective. In this work, we develop new acoustic modeling techniques that optimize spatial filtering and long short-term memory (LSTM) layers from multi-channel (MC) input based on an ASR criterion directly.
- Categories:
24 Views
- Read more about REINFORCEMENT LEARNING BASED SPEECH ENHANCEMENT FOR ROBUST SPEECH RECOGNITION
- Log in to post comments
- Categories:
63 Views
- Read more about Subband Temporal Envelope Features and Data Augmentation for End-to-end Recognition of Distant Conversational Speech
- Log in to post comments
This paper investigates the use of subband temporal envelope (STE) features and speed perturbation based data augmentation in end-to-end recognition of distant conversational speech in everyday home environments. STE features track energy peaks in perceptual frequency bands which reflect the resonant properties of the vocal tract. Data augmentation is performed by adding more training data obtained after modifying the speed of the original training data.
- Categories:
49 Views