- Read more about Flow-Based Fast Multichannel Nonnegative Matrix Factorization for Blind Source Separation
- Log in to post comments
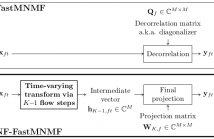
This paper describes a blind source separation method for multichannel audio signals, called NF-FastMNMF, based on the integration of the normalizing flow (NF) into the multichannel nonnegative matrix factorization with jointly-diagonalizable spatial covariance matrices, a.k.a. FastMNMF.
- Categories:
 115 Views
115 Views
- Read more about SKIPPING MEMORY LSTM FOR LOW-LATENCY REAL-TIME CONTINUOUS SPEECH SEPARATION
- Log in to post comments
Continuous speech separation for meeting pre-processing has recently become a focused research topic. Compared to the data in utterance-level speech separation, the meeting-style audio stream lasts longer, has an uncertain number of speakers. We adopt the time-domain speech separation method and the recently proposed Graph-PIT to build a super low-latency online speech separation model, which is very important for the real application. The low-latency time-domain encoder with a small stride leads to an extremely long feature sequence.
poster.pdf
- Categories:
26 Views
- Read more about Multi-frame Full-rank Spatial Covariance Analysis for Underdetermined BSS in Reverberant Environment
- Log in to post comments
Full-rank spatial covariance analysis (FCA) is a blind source separation (BSS) method, and can be applied to underdetermined cases where the sources outnumber the microphones. This paper proposes a new extension of FCA, aiming to improve BSS performance for mixtures in which the length of reverberation exceeds the analysis frame. There has already been proposed a model that considers delayed source components as the exceeded parts. In contrast, our new extension models multiple time frames with multivariate Gaussian distributions of larger dimensionality than the existing FCA models.
- Categories:
92 Views
- Read more about On loss functions and evaluation metrics for music source separation
- Log in to post comments
We investigate which loss functions provide better separations via
benchmarking an extensive set of those for music source separation.
To that end, we first survey the most representative audio source
separation losses we identified, to later consistently benchmark them
in a controlled experimental setup. We also explore using such losses
as evaluation metrics, via cross-correlating them with the results of
a subjective test. Based on the observation that the standard signal-
to-distortion ratio metric can be misleading in some scenarios, we
- Categories:
95 Views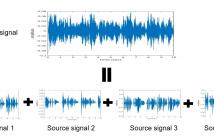
- Read more about HARVESTING PARTIALLY-DISJOINT TIME-FREQUENCY INFORMATION FOR IMPROVING DEGENERATE UNMIXING ESTIMATION TECHNIQUE
- Log in to post comments
The degenerate unmixing estimation technique (DUET) is one of the most efficient blind source separation algorithms tackling the challenging situation when the number of sources exceeds the number of microphones. However, as a time-frequency mask-based method, DUET erroneously results in interference components retention when source signals overlap each other in both frequency and time domains.
slides.pdf
- Categories:
19 Views
- Read more about Uformer: A Unet Based Dilated Complex & Real Dual-path Conformer Network for Simultaneous Speech Enhancement and Dereverberation
- Log in to post comments
- Categories:
24 Views
- Read more about HARMONICITY PLAYS A CRITICAL ROLE IN DNN BASED VERSUS IN BIOLOGICALLY-INSPIRED MONAURAL SPEECH SEGREGATION SYSTEMS
- Log in to post comments
Recent advancements in deep learning have led to drastic improvements in speech segregation models. Despite their success and growing applicability, few efforts have been made to analyze the underlying principles that these networks learn to perform segregation. Here we analyze the role of harmonicity on two state-of-the-art Deep Neural Networks (DNN)-based models- Conv-TasNet and DPT-Net. We evaluate their performance with mixtures of natural speech versus slightly manipulated inharmonic speech, where harmonics are slightly frequency jittered.
Parikh_poster.pdf
Parikh_CR.pdf
- Categories:
15 Views
- Read more about Ray-Space-Based Multichannel Nonnegative Matrix Factorization for Audio Source Separation
- Log in to post comments
Nonnegative matrix factorization (NMF) has been traditionally considered a promising approach for audio source separation. While standard NMF is only suited for single-channel mixtures, extensions to consider multi-channel data have been also proposed. Among the most popular alternatives, multichannel NMF (MNMF) and further derivations based on constrained spatial covariance models have been successfully employed to separate multi-microphone convolutive mixtures.
- Categories:
11 Views
- Read more about TIME-DOMAIN AUDIO-VISUAL SPEECH SEPARATION ON LOW QUALITY VIDEOS
- Log in to post comments
Incorporating visual information is a promising approach to improve the performance of speech separation. Many related works have been conducted and provide inspiring results. However, low quality videos appear commonly in real scenarios, which may significantly degrade the performance of normal audio-visual speech separation system. In this paper, we propose a new structure to fuse the audio and visual features, which uses the audio feature to select relevant visual features by utilizing the attention mechanism.
poster.pdf
presentation.pptx
- Categories:
22 Views