Documents
Presentation Slides
Deep Multi-Frame MVDR Filtering for Single-Microphone Speech Enhancement -- Slides
- Citation Author(s):
- Submitted by:
- Marvin Tammen
- Last updated:
- 22 June 2021 - 3:58am
- Document Type:
- Presentation Slides
- Document Year:
- 2021
- Event:
- Presenters:
- Marvin Tammen
- Paper Code:
- SS-13.6
- Categories:
- Log in to post comments
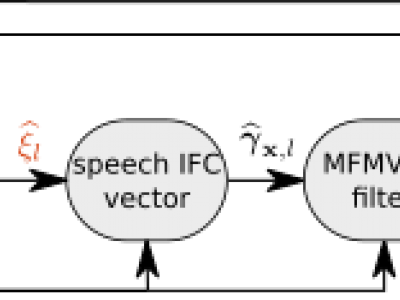
Multi-frame algorithms for single-microphone speech enhancement, e.g., the multi-frame minimum variance distortionless response (MFMVDR) filter, are able to exploit speech correlation across adjacent time frames in the short-time Fourier transform (STFT) domain. Provided that accurate estimates of the required speech interframe correlation vector and the noise correlation matrix are available, it has been shown that the MFMVDR filter yields a substantial noise reduction while hardly introducing any speech distortion. Aiming at merging the speech enhancement potential of the MFMVDR filter and the estimation capability of temporal convolutional networks (TCNs), in this paper we propose to embed the MFMVDR filter within a deep learning framework. The TCNs are trained to map the noisy speech STFT coefficients to the required quantities by minimizing the scale-invariant signal-to-distortion ratio loss function at the MFMVDR filter output. Experimental results show that the proposed deep MFMVDR filter achieves a competitive speech enhancement performance on the Deep Noise Suppression Challenge dataset. In particular, the results show that estimating the parameters of an MFMVDR filter yields a higher performance in terms of PESQ and STOI than directly estimating the multi-frame filter or single-frame masks and than Conv-TasNet.

