Documents
Presentation Slides
DISCOURSE-LEVEL PROSODY MODELING WITH A VARIATIONAL AUTOENCODER FOR NON-AUTOREGRESSIVE EXPRESSIVE SPEECH SYNTHESIS
- Citation Author(s):
- Submitted by:
- Ningqian Wu
- Last updated:
- 10 May 2022 - 11:18am
- Document Type:
- Presentation Slides
- Document Year:
- 2022
- Event:
- Presenters:
- Ning-Qian Wu
- Paper Code:
- SPE-55.4
- Categories:
- Log in to post comments
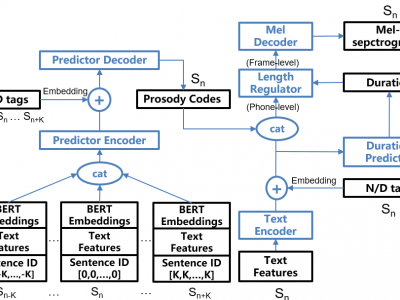
To address the issue of one-to-many mapping from phoneme sequences to acoustic features in expressive speech synthesis, this paper proposes a method of discourse-level prosody modeling with a variational autoencoder (VAE) based on the non-autoregressive architecture of FastSpeech. In this method, phone-level prosody codes are extracted from prosody features by combining VAE with FastSpeech, and are predicted using discourse-level text features together with BERT embeddings. The continuous wavelet transform (CWT) in FastSpeech2 for F0 representation is not necessary anymore. Experimental results on a Chinese audiobook dataset show that our proposed method can effectively take advantage of discourse-level linguistic information and has outperformed FastSpeech2 on the naturalness and expressiveness of synthetic speech.

