Documents
Poster
DT-NeRF: Decomposed Triplane-Hash Neural Radiance Fields for High-Fidelity Talking Portrait Synthesis
- DOI:
- 10.60864/keve-yf08
- Citation Author(s):
- Submitted by:
- yaoyu su
- Last updated:
- 6 June 2024 - 10:32am
- Document Type:
- Poster
- Document Year:
- 2024
- Event:
- Presenters:
- Yaoyu Su
- Paper Code:
- IVMSP-P4.2
- Categories:
- Log in to post comments
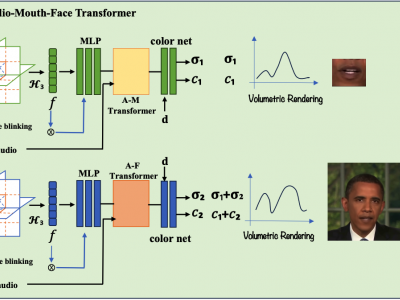
In this paper, we present the decomposed triplane-hash neural radiance fields (DT-NeRF), a framework that significantly improves the photorealistic rendering of talking faces and achieves state-of-the-art results on key evaluation datasets. Our architecture decomposes the facial region into two specialized triplanes: one specialized for representing the mouth, and the other for the broader facial features. We introduce audio features as residual terms and integrate them as query vectors into our model through an audio-mouthface transformer. Additionally, our method leverages the capabilities of Neural Radiance Fields (NeRF) to enrich the volumetric representation of the entire face through additive volumetric rendering techniques. Comprehensive experimental evaluations corroborate the effectiveness and superiority of our proposed approach.

