Documents
Presentation Slides
End-to-End Lyrics Alignment Using An Audio-to-Character Recognition Model
- Citation Author(s):
- Submitted by:
- Daniel Stoller
- Last updated:
- 17 May 2019 - 5:14am
- Document Type:
- Presentation Slides
- Document Year:
- 2019
- Event:
- Presenters:
- Daniel Stoller
- Paper Code:
- AASP-L7
- Categories:
- Log in to post comments
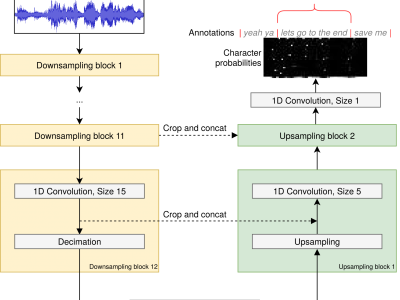
Time-aligned lyrics can enrich the music listening experience by enabling karaoke, text-based song retrieval and intra-song navigation, and other applications. Compared to text-to-speech alignment, lyrics alignment remains highly challenging, despite many attempts to combine numerous sub-modules including vocal separation and detection in an effort to break down the problem. Furthermore, training required fine-grained annotations to be available in some form. Here, we present a novel system based on a modified Wave-U-Net architecture, which predicts character probabilities directly from raw audio using learnt multi-scale representations of the various signal components. There are no sub-modules whose interdependencies need to be optimized. Our training procedure is designed to work with weak, line-level annotations available in the real world. With a mean alignment error of 0.35s on a standard dataset our system outperforms the state-of-the-art by an order of magnitude.

