
ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The 2019 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit website.

- Read more about A DOUBLE-CROSS-CORRELATION PROCESSOR FOR BLIND SAMPLING RATE OFFSET ESTIMATION IN ACOUSTIC SENSOR NETWORKS
- Log in to post comments
Signal synchronization in wireless acoustic sensor networks requires an accurate estimation of the sampling rate offset (SRO) inevitably present in signals acquired by sensors of ad-hoc networks. Although some sophisticated methods for blind SRO estimation have been recently proposed in this very young field of research, there is still a need for the development of new ideas and concepts especially regarding robust approaches with low computational complexity.
- Categories:
 48 Views
48 Views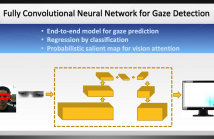
- Read more about Estimation of gaze region using two dimensional probabilistic maps constructed using convolutional neural networks
- Log in to post comments
Predicting the gaze of a user can have important applications in hu- man computer interactions (HCI). They find applications in areas such as social interaction, driver distraction, human robot interaction and education. Appearance based models for gaze estimation have significantly improved due to recent advances in convolutional neural network (CNN). This paper proposes a method to predict the gaze of a user with deep models purely based on CNNs.
- Categories:
42 Views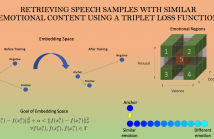
- Read more about Retrieving speech samples with similar emotional content using a triplet loss function
- Log in to post comments
The ability to identify speech with similar emotional content is valuable to many applications, including speech retrieval, surveil- lance, and emotional speech synthesis. While current formulations in speech emotion recognition based on classification or regression are not appropriate for this task, solutions based on preference learn- ing offer appealing approaches for this task. This paper aims to find speech samples that are emotionally similar to an anchor speech sample provided as a query. This novel formulation opens interest- ing research questions.
- Categories:
60 Views
- Read more about On the Transferability of Adversarial Examples Against CNN-Based Image Forensics
- Log in to post comments
Recent studies have shown that Convolutional Neural Networks (CNN) are relatively easy to attack through the generation of so-called adversarial examples. Such vulnerability also affects CNN-based image forensic tools. Research in deep learning has shown that adversarial examples exhibit a certain degree of transferability, i.e., they maintain part of their effectiveness even against CNN models other than the one targeted by the attack. This is a very strong property undermining the usability of CNN’s in security-oriented applications.
- Categories:
122 Views
- Read more about LMS: PAST, PRESENT AND FUTURE: Puzzles, Problems and Potentials
- Log in to post comments
We give a brief history of the performance analysis of LMS.
Using averaging theory we show when and why the ‘independence
assumption’ ‘works’; we preface this with a fast
heuristic explanation of averaging methods, clarifying their
connection to the ‘ODE’ method. We then extend the discussion
to more recent distributed versions such as diffusion
LMS and consensus. While single node LMS is a single timescale
algorithm it turns out that distributed versions are twotime
scale systems, something that is not yet widely understood.
- Categories:
144 Views
- Read more about Speech Landmark Bigrams for Depression Detection from Naturalistic Smartphone Speech
- Log in to post comments
Detection of depression from speech has attracted significant research attention in recent years but remains a challenge, particularly for speech from diverse smartphones in natural environments. This paper proposes two sets of novel features based on speech landmark bigrams associated with abrupt speech articulatory events for depression detection from smartphone audio recordings. Combined with techniques adapted from natural language text processing, the proposed features further exploit landmark bigrams by discovering latent articulatory events.
- Categories:
97 Views
- Read more about Graph Signal Sampling via Reinforcement Learning
- Log in to post comments
We model the sampling and recovery of clustered graph signals as a reinforcement learning (RL) problem. The signal sampling is carried out by an agent which crawls over the graph and selects the most relevant graph nodes to sample. The goal of the agent is to select signal samples which allow for the most accurate recovery. The sample selection is formulated as a multi-armed bandit (MAB) problem, which lends naturally to learning efficient sampling strategies using the well-known gradient MAB algorithm.
- Categories:
122 Views
- Read more about ROBUST M-ESTIMATION BASED MATRIX COMPLETION
- Log in to post comments
Conventional approaches to matrix completion are sensitive to outliers and impulsive noise. This paper develops robust and computationally efficient M-estimation based matrix completion algorithms. By appropriately arranging the observed entries, and then applying alternating minimization, the robust matrix completion problem is converted into a set of regression M-estimation problems. Making use of differ- entiable loss functions, the proposed algorithm overcomes a weakness of the lp-loss (p ≤ 1), which easily gets stuck in an inferior point.
- Categories:
111 Views
Consider a network with N nodes in d dimensions, and M overlapping subsets P_1,...,P_M (subnetworks). Assume that the nodes in a given P_i are observed in a local coordinate system. We wish to register the subnetworks using the knowledge of the observed coordinates. More precisely, we want to compute the positions of the N nodes in a global coordinate system, given P_1,...,P_M and the corresponding local coordinates. Among other applications, this problem arises in divide-and-conquer algorithms for localization of adhoc sensor networks.
- Categories:
31 Views
- Read more about Speech Emotion Recognition Using Multi-hop Attention Mechanism
- Log in to post comments
In this paper, we are interested in exploiting textual and acoustic data of an utterance for the speech emotion classification task. The baseline approach models the information from audio and text independently using two deep neural networks (DNNs). The outputs from both the DNNs are then fused for classification. As opposed to using knowledge from both the modalities separately, we propose a framework to exploit acoustic information in tandem with lexical data.
- Categories:
271 Views