Documents
Poster
Fusing Information Streams in End-to-End Audio-Visual Speech Recognition
- Citation Author(s):
- Submitted by:
- Wentao Yu
- Last updated:
- 22 June 2021 - 9:39am
- Document Type:
- Poster
- Document Year:
- 2021
- Event:
- Presenters:
- Wentao Yu
- Paper Code:
- MLSP-24.6
- Categories:
- Log in to post comments
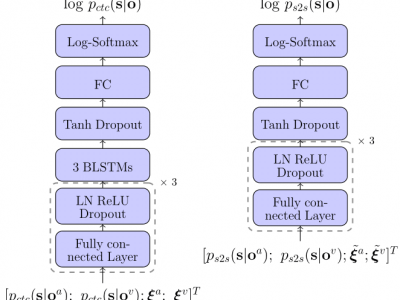
End-to-end acoustic speech recognition has quickly gained widespread popularity and shows promising results in many studies. Specifically the joint transformer/CTC model provides very good performance in many tasks. However, under noisy and distorted conditions, the performance still degrades notably. While audio-visual speech recognition can significantly improve the recognition rate of end-to-end models in such poor conditions, it is not obvious how to best utilize any available information on acoustic and visual signal quality and reliability in these models. We thus consider the question of how to optimally inform the transformer/CTC model of any time-variant reliability of the acoustic and visual information streams. We propose a new fusion strategy, incorporating reliability information in a decision fusion net that considers the temporal effects of the attention
mechanism. This approach yields significant improvements compared to a state-of-the-art baseline model on the Lip Reading Sentences 2 and 3 (LRS2 and LRS3) corpus. On average, the new system achieves a relative word error rate reduction of 43% compared to the audio-only setup and 31% compared to the audiovisual end-to-end baseline.

