Documents
Poster
Improving Run Length Encoding by Preprocessing
- Citation Author(s):
- Submitted by:
- Sven Fiergolla
- Last updated:
- 28 February 2021 - 11:04am
- Document Type:
- Poster
- Document Year:
- 2021
- Event:
- Presenters:
- Sven Fiergolla and Petra Wolf
- Categories:
- Keywords:
- Log in to post comments
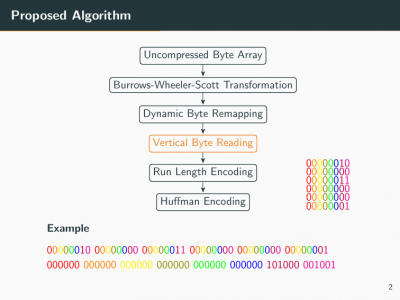
The Run Length Encoding (RLE) compression method is a long standing simple lossless compression scheme which is easy to implement and achieves a good compression on input data which contains repeating consecutive symbols. In its pure form RLE is not applicable on natural text or other input data with short sequences of identical symbols. We present a combination of preprocessing steps that turn arbitrary input data in a byte-wise encoding into a bit-string which is highly suitable for RLE compression. The main idea is to first read all most significant bits of the input byte-string, followed by the second most significant bit and so on. We combine this approach by a dynamic byte remapping as well as a Burrows-Wheeler-Scott transform on a byte level. Finally, we apply a Huffman Encoding on the output of the bit-wise RLE encoding to allow for more dynamic lengths of code words encoding runs of the RLE. With our technique we can achieve a lossless average compression which is better than the standard RLE compression by a factor of 8 on average.


Comments
Comparison with standard approaches?
Thanks for this poster presentation.
I think your ideas have potential, but need further analysis.
The first thing I noted when reading your arXiv pre-print is that there is no discussion about how to extract the BWST (Burrows-Wheeler-Scott transform)
from the C library LibDivSufSort. As far as I am aware of, this library computes the standard BWT, not the bijective one.
There is an arXiv paper [1] available on how to compute the BWST in linear time, but unfortunately, there is currently no implementation available.
Regarding compression, the common approach used for the Burrows-Wheeler transform is to apply a move-to-front (MTF) encoding, then a run-length encoding (RLE),
and finally a Huffman coding. You can see in [2, Table 2] (aliased as bwtzip), that this already gives a good compression.
In that sense, your comparison of your proposed compression scheme with just the plain RLE is unfair.
It would make much more sense to compare it against BWT+MTF+RLE+Huffman or BWST+MTF+RLE+Huffman.
In particular, I would be really interested in seeing whether (a) BWTS or BWT, as well as whether (b) MTF or Dynamic-Byte-Remapping+Vertical-Byte-Reading does a better job.
[1]: https://arxiv.org/abs/1911.06985
[2]: https://drops.dagstuhl.de/opus/volltexte/2017/7601/