
In this paper, we propose a novel approach to succinct coding of permutations taking advantage of the “divide-and-conquer” strategy. In addition, we provide a theoretical analysis of the proposed approach leading to formulations allowing to calculate precise bounds (minimum, average, maximum) to the length of permutation coding expressed in a number of bits per permutation element for various sizes of permutations n being integer powers of 2.
- Categories:
 104 Views
104 Views
- Read more about Counting with Prediction: Rank and Select Queries with Adjusted Anchoring
- 1 comment
- Log in to post comments
Rank and select queries are the fundamental building blocks of the compressed data structures. On a given bit string of length n, counting the number of set bits up to a certain position is named as the rank, and finding the position of the kth set bit is the select query. We present a new data structure and the procedures on it to support rank/select operations.
- Categories:
120 Views
- Read more about Compressing Multisets with Large Alphabets
- Log in to post comments
Current methods which compress multisets at an optimal rate have computational complexity that scales linearly with alphabet size, making them too slow to be practical in many real-world settings. We show how to convert a compression algorithm for sequences into one for multisets, in exchange for an additional complexity term that is quasi-linear in sequence length. This allows us to compress multisets of independent and identically distributed symbols at an optimal rate, with computational complexity decoupled from the alphabet size.
- Categories:
212 Views
- Read more about A Benchmark of Entropy Coders for the Compression of Genome Sequencing Data
- 1 comment
- Log in to post comments
Genomic sequencing data contain three different data fields: read names, quality values, and nucleotide sequences. In this work, a variety of entropy encoders and compression algorithms were benchmarked in terms of compression-decompression rates and times separately for each data field as raw data from FASTQ files (implemented in the Fastq analysis script) and in MPEG-G uncompressed descriptor symbols decoded from MPEG-G bitstreams (implemented in the symbols analysis script).
- Categories:
137 Views
- Read more about MPEG-G Reference-Based Compression of Unaligned Reads Through Ultra-Fast Alignments
- 1 comment
- Log in to post comments
With the widespread application of next generation sequencing technologies, the volume of sequencing data became comparable to that of big data domains. The compression of sequencing reads (nucleotide sequences, quality values, read names), in both raw and aligned data, is a way to alleviate bandwidth, transfer, and storage requirements of genomics pipelines. ISO/IEC MPEG-G standardizes the compressed representation (i.e. storage and streaming) of structured, indexed sets of genomic sequencing data for both raw and aligned data.
- Categories:
48 Views
- Read more about Backward Weighted Coding
- Log in to post comments
Extending recently suggested methods, a new dynamic compression algorithm is proposed, which assigns larger weights to characters that have just been coded by means of an increasing weight function. Empirical results present its efficient compression performance, which, for input files with locally skewed distributions, can improve beyond the lower bound given by the entropy for static encoding, at the price of slower running times for compression, and comparable time for decompression.
- Categories:
71 Views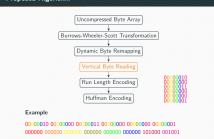
The Run Length Encoding (RLE) compression method is a long standing simple lossless compression scheme which is easy to implement and achieves a good compression on input data which contains repeating consecutive symbols. In its pure form RLE is not applicable on natural text or other input data with short sequences of identical symbols. We present a combination of preprocessing steps that turn arbitrary input data in a byte-wise encoding into a bit-string which is highly suitable for RLE compression.
- Categories:
355 Views
- Read more about A high efficient cascade coder with predictor blending method for lossless audio compression
- Log in to post comments
In this paper, the improvement of the cascaded prediction method was presented. The prediction method with backward adaptation and extended Ordinary Least Square (OLS+) was presented. An own approach to implementation of the effective context-dependent constant component removal block was used. Also the improved adaptive arithmetic coder with short, medium and long-term adaptation was used and the experiment was carried out comparing the results with other known lossless audio coders against which our method obtained the best efficiency.
- Categories:
39 Views
- Read more about Reverse Multi-Delimiter Compression Codes
- Log in to post comments
An enhanced version of a recently introduced family of variable length binary codes with multiple pattern delimiters is presented and discussed. These codes are complete, universal, synchronizable, they have monotonic indexing and allow a standard search in compressed files. Comparing the compression rate on natural language texts demonstrates that introduced codes appear to be much superior to other known codes with similar properties. A fast byte-aligned decoding algorithm is constructed, which operates much faster than the one for Fibonacci codes.
- Categories:
58 Views
- Read more about Re-Pair in Small Space
- Log in to post comments
Re-Pair is a grammar compression scheme with favorably good compression rates. The computation of Re-Pair comes with the cost of maintaining large frequency tables, which makes it hard to compute Re-Pair on large scale data sets. As a solution for this problem we present, given a text of length n whose characters are drawn from an integer alphabet, an O(n^2) time algorithm computing Re-Pair in n lg max(n, τ) bits of working space including the text space, where τ is the number of terminals and non-terminals.
repair.pdf
- Categories:
96 Views