Documents
Poster
[Poster] Crowdsourced and Automatic Speech Prominence Estimation
- DOI:
- 10.60864/tjwe-4j94
- Citation Author(s):
- Submitted by:
- Max Morrison
- Last updated:
- 6 June 2024 - 10:28am
- Document Type:
- Poster
- Document Year:
- 2024
- Event:
- Presenters:
- Max Morrison
- Paper Code:
- SLP-P31.13
- Categories:
- Log in to post comments
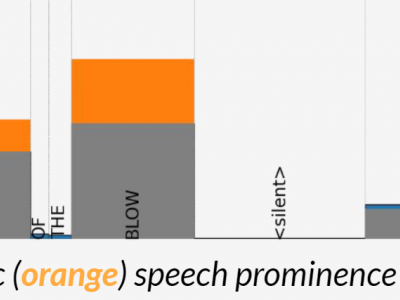
The prominence of a spoken word is the degree to which an average native listener perceives the word as salient or emphasized relative to its context. Speech prominence estimation is the process of assigning a numeric value to the prominence of each word in an utterance. These prominence labels are useful for linguistic analysis, as well as training automated systems to perform emphasis-controlled text-to-speech or emotion recognition. Manually annotating prominence is time-consuming and expensive, which motivates the development of automated methods for speech prominence estimation. However, developing such an automated system using machine-learning methods requires human-annotated training data. Using our system for acquiring such human annotations, we collect and open-source crowdsourced annotations of a portion of the LibriTTS dataset. We use these annotations as ground truth to train a neural speech prominence estimator that generalizes to unseen speakers, datasets, and speaking styles. We investigate design decisions for neural prominence estimation as well as how neural prominence estimation improves as a function of two key factors of annotation cost: dataset size and the number of annotations per utterance.

