Documents
Poster
SELF-SUPERVISED LEARNING METHOD USING MULTIPLE SAMPLING STRATEGIES FOR GENERAL-PURPOSE AUDIO REPRESENTATION
- Citation Author(s):
- Submitted by:
- Ibuki Kuroyanagi
- Last updated:
- 6 May 2022 - 3:28am
- Document Type:
- Poster
- Document Year:
- 2022
- Event:
- Presenters:
- Ibuki Kuroyanagi
- Paper Code:
- MLSP-6.3
- Categories:
- Log in to post comments
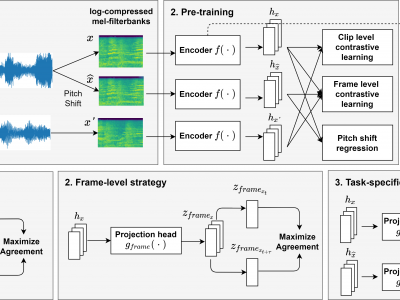
We propose a self-supervised learning method using multiple sampling strategies to obtain general-purpose audio representation. Multiple sampling strategies are used in the proposed method to construct contrastive losses from different perspectives and learn representations based on them. In this study, in addition to the widely used clip-level sampling strategy, we introduce two new strategies, a frame-level strategy and a task-specific strategy. The proposed multiple strategies improve the performance of frame-level classification and other tasks like pitch detection, which are not the focus of the conventional single clip-level sampling strategy. We pre-trained the method on a subset of Audioset and applied it to a downstream task with frozen weights. The proposed method improved clip classification, sound event detection, and pitch detection performance by 25 %, 20 %, and 3.6 %.

