Documents
Presentation Slides
Towards an ASR Approach Using Acoustic and Language Models for Speech Enhancement
- Citation Author(s):
- Submitted by:
- KHANDOKAR MD NAYEM
- Last updated:
- 24 June 2021 - 4:06pm
- Document Type:
- Presentation Slides
- Document Year:
- 2021
- Event:
- Presenters:
- Khandokar Md. Nayem
- Paper Code:
- SPE-51.6
- Categories:
- Log in to post comments
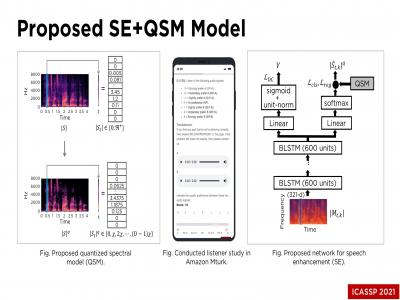
Recent work has shown that deep-learning based speech enhancement performs best when a time-frequency mask is estimated. Unlike speech, these masks have a small range of values that better facilitate regression-based learning. The question remains whether neural-network based speech estimation should be treated as a regression problem. In this work, we propose to modify the speech estimation process, by treating speech enhancement as a classification problem in an ASR-style manner. More specifically, we propose a quantized speech prediction model that classifies speech spectra into a corresponding quantized class. We then train and apply a language-style model that learns the transition probabilities of the quantized classes to ensure more realistic speech spectra. We compare our approach against time-frequency masking approaches, and the results show that our quantized spectra approach leads to improvements.

