Documents
Video of presentation
Low Delay Robust Audio Coding by Noise Shaping, Fractional Sampling, and Source Prediction
- Citation Author(s):
- Submitted by:
- Jan Ostergaard
- Last updated:
- 28 February 2021 - 10:09am
- Document Type:
- Video of presentation
- Document Year:
- 2021
- Event:
- Presenters:
- Jan Ostergaard
- Categories:
- Log in to post comments
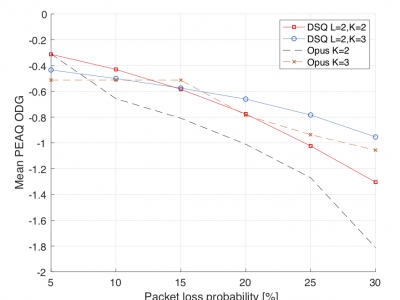
It was recently shown that the combination of source prediction, two-times oversampling, and noise shaping, can be used to obtain a robust (multiple-description) audio coding frame- work for networks with packet loss probabilities less than 10%. Specifically, it was shown that audio signals could be encoded into two descriptions (packets), which were separately sent over a communication channel. Each description yields a desired performance by itself, and when they are combined, the performance is improved. This paper extends the previous work to an arbitrary number of descriptions (packets) by using fractional oversampling and a new decoding principle. We demonstrate that, due to source aliasing, existing MSE optimized reconstruction rules from noisy sampled data, performs poorly from a perceptual point of view. A simple reconstruction rule is proposed, that improves the PEAQ objective difference grades (ODG) by more than 2 points. The proposed audio coder enables low- delay high-quality audio streaming on networks with late packet arrivals or packet losses. With a coding delay of 2.5 ms, and a total bitrate of 300 kbps, it is demonstrated that mean PEAQ ODGs around -0.65 can be obtained for 48 kHz (mono) music (pop & rock), and packet loss probabilities of 20%.

