- Read more about LA-VocE: Low-SNR Audio-visual Speech Enhancement using Neural Vocoders
- Log in to post comments
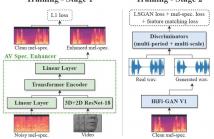
Audio-visual speech enhancement aims to extract clean speech from a noisy environment by leveraging not only the audio itself but also the target speaker's lip movements. This approach has been shown to yield improvements over audio-only speech enhancement, particularly for the removal of interfering speech. Despite recent advances in speech synthesis, most audio-visual approaches continue to use spectral mapping/masking to reproduce the clean audio, often resulting in visual backbones added to existing speech enhancement architectures.
- Categories:
 39 Views
39 Views