- Read more about MULTI-EXIT VISION TRANSFORMER WITH CUSTOM FINE-TUNING FOR FINE-GRAINED IMAGE RECOGNITION
- Log in to post comments
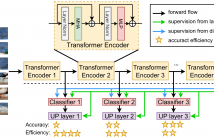
Capturing subtle visual differences between subordinate categories is crucial for improving the performance of Finegrained Visual Classification (FGVC). Recent works proposed deep learning models based on Vision Transformer (ViT) to take advantage of its self-attention mechanism to locate important regions of the objects and extract global information. However, their large number of layers with self-attention mechanism requires intensive computational cost and makes them impractical to be deployed on resource-restricted hardware including internet of things (IoT) devices.
- Categories:
 64 Views
64 Views