| Type | Title | Author | Replies | Last updated |
|---|---|---|---|---|
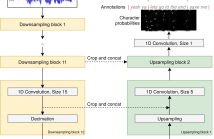
| Document | End-to-End Lyrics Alignment Using An Audio-to-Character Recognition Model | Daniel Stoller | 0 | 6 years 10 months ago |
| Document | Semi-Supervised Adversarial Audio Source Separation applied to Singing Voice Extraction | Daniel Stoller | 0 | 7 years 10 months ago |
Primary tabs
Author's Documents
9 May 2019 - 12:22pm 4303 Downloads

15 April 2018 - 6:00pm 601 Downloads