
The International Conference on Image Processing (ICIP), sponsored by the IEEE Signal Processing Society, is the premier forum for the presentation of technological advances and research results in the fields of theoretical, experimental, and applied image and video processing. ICIP has been held annually since 1994, brings together leading engineers and scientists in image and video processing from around the world. Visit website.

- Read more about EFFICIENT IMPROVEMENT METHOD FOR SEPARATION OF REFLECTION COMPONENTS BASED ON AN ENERGY FUNCTION
- Log in to post comments
In this paper, we propose a novel and effective method for improving the accuracy of separating reflection components in a single image based on the dichromatic reflection model after calculating the diffuse reflection component by any existing method. Separating reflection components accurately is very important and useful in computer vision to detect highlight areas, which are often regarded as outliers, and to enhance image quality, especially texture, because we can control the intensity and apply a filter independently to each reflection component.
- Categories:
 34 Views
34 Views
High-fidelity virtual content is essential for the creation of compelling and effective virtual reality (VR) experiences.
- Categories:
6 Views- Read more about ICIP 2017 Paper #2528: 3D CONVOLUTIONAL NEURAL NETWORK WITH MULTI-MODEL FRAMEWORK FOR ACTION RECOGNITION
- Log in to post comments
- Categories:
57 Views
- Read more about SELF-PACED LEAST SQUARE SEMI-COUPLED DICTIONARY LEARNING FOR PERSON RE-IDENTIFICATION
- Log in to post comments
Person re-identification aims to match people across disjoint camera views. It has been reported that Least Square
Semi-Coupled Dictionary Learning (LSSCDL) based samplespecific SVM learning framework has obtained the state of
the art performance. However, the objective function of the LSSCDL, the algorithm of learning the pairs (feature, weight)
dictionaries and the mapping function between feature space and weight space, is non-convex, which usually result in
- Categories:
8 Views
- Read more about A data-driven approach to feature space selection for robust micro-endoscopic image reconstruction
- Log in to post comments
- Categories:
9 Views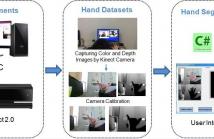
Hand segmentation is a fundamental technology in computer vision, which is used as a pre-processing step for various applications such as human-computer interaction (HCI), sign language translation, and medical systems. This demo provides interaction-free hand segmentation using Kinect camera. It is completely automatic, which can automatically segment foreground from the background and select the seed on the depth image for hand segmentation using Kinect camera.
- Categories:
13 Views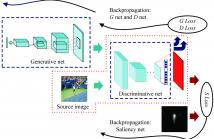
- Read more about AN ACCURATE SALIENCY PREDICTION METHOD BASED ON GENERATIVE ADVERSARIAL NETWORKS
- Log in to post comments
In this paper, we propose a saliency prediction algorithm utilizing generative adversarial networks. The proposed system contains two parts: saliency network and adversarial networks. The saliency network is the basis for saliency prediction, which calculates an Euclidean cost function on the grayscale values between the predicted saliency map and the ground truth. In order to improve the accuracy of the algorithm, adversarial networks are subsequently utilized to extract the features of input data by coordinating the learning rates of the two sub-networks contained in the networks.
- Categories:
23 Views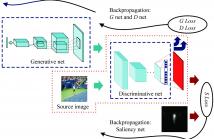
In this paper, we propose an accurate generative adversarial networks based saliency prediction model. Saliency network is an intact model to produce saliency maps. With the help of adversarial networks, feature extraction is more smooth and thorough. Moreover, the fully convolutional networks in saliency network facilitate the continuity and accuracy of pixel values in a saliency map. Compared with the six stateof-the-art methods, the proposed model has achieved highest accuracy. Besides, the performance of our model indicates that adversarial networks could be applied to more than classification. For future work, we will extend the algorithm to semi-supervised saliency prediction since DCGAN is a strong candidate for unsupervised learning.
- Categories:
6 Views
- Read more about A Novel Kinect V2 Registration Method For Large-Displacement Environments Using Camera And Scene Constraints
- Log in to post comments
In a lot of multi-Kinect V2-based systems, the registration of these Kinect V2 sensors is an important step which directly affects the system precision. The coarse-to-fine method using calibration objects is an effective way to solve the Kinect V2 registration problem. However, for the registration of Kinect V2 cameras with large displacements, this kind of method may fail. To this end, a novel Kinect V2 registration method, which is also based on the coarse-to-fine framework, is proposed by using camera and scene constraints.
- Categories:
68 Views- Read more about EFFECT OF WAVELET AND HYBRID CLASSIFICATION ON ACTION RECOGNITION
- Log in to post comments
- Categories:
3 Views