Documents
Poster
AttS2S-VC: Sequence-to-Sequence Voice Conversion with Attention and Context Preservation Mechanisms
- Citation Author(s):
- Submitted by:
- Kou Tanaka
- Last updated:
- 15 May 2019 - 7:03am
- Document Type:
- Poster
- Document Year:
- 2019
- Event:
- Presenters:
- Kou Tanaka
- Paper Code:
- 2505
- Categories:
- Keywords:
- Log in to post comments
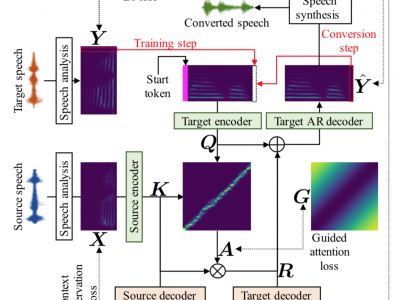
This paper describes a method based on a sequence-to-sequence learning (Seq2Seq) with attention and context preservation mechanism for voice conversion (VC) tasks. Seq2Seq has been outstanding at numerous tasks involving sequence modeling such as speech synthesis and recognition, machine translation, and image captioning. In contrast to current VC techniques, our method 1) stabilizes and accelerates the training procedure by considering guided attention and proposed context preservation losses, 2) allows not only spectral envelopes but also fundamental frequency contours and durations of speech to be converted, 3) requires no context information such as phoneme labels, and 4) requires no time-aligned source and target speech data in advance. In our experiment, the proposed VC framework can be trained in only one day, using only one GPU of an NVIDIA Tesla K80, while the quality of the synthesized speech is higher than that of speech converted by Gaussian mixture model-based VC and is comparable to that of speech generated by recurrent neural network-based text-to-speech synthesis, which can be regarded as an upper limit on VC performance.

