Documents
Poster
CIF-RNNT: Streaming ASR via Acoustic Word Embeddings with Continuous Integrate-and-Fire and RNN-Transducers
- Citation Author(s):
- Submitted by:
- Wen Shen Teo
- Last updated:
- 14 April 2024 - 11:35pm
- Document Type:
- Poster
- Document Year:
- 2024
- Event:
- Presenters:
- Teo Wen Shen
- Paper Code:
- 3388
- Categories:
- Log in to post comments
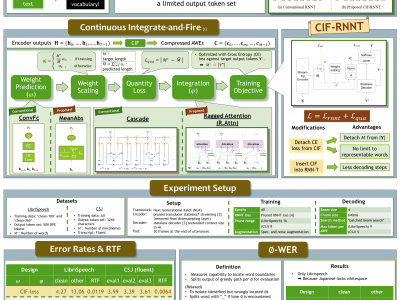
This paper introduces CIF-RNNT, a model that incorporates Continuous Integrate-and-Fire into RNN-Transducers (RNNTs) for streaming ASR via acoustic word embeddings (AWEs). CIF can dynamically compress long sequences into shorter ones, while RNNTs can produce multiple symbols given an input vector. We demonstrate that our model can not only streamingly segment acoustic information and produce AWEs, but also recover the represented word using a fixed set of output tokens with a shorter decoding time. Moreover, we improved CIF with new mechanisms that outperformed conventional ones when evaluated on Japanese and English ASR datasets. As the first attempt at combining CIF with RNNT, this paper advances our understanding of applying CIF’s dynamic compression capabilities to obtain AWEs for streaming ASR and paves the way for speech and text integration via words instead of architecturally confined tokens.

