Documents
Research Manuscript
Communication-Efficient Federated Learning through Adaptive Weight Clustering and Server-Side Distillation
- DOI:
- 10.60864/q0ew-hj08
- Citation Author(s):
- Submitted by:
- Vasileios Tsouvalas
- Last updated:
- 6 June 2024 - 10:27am
- Document Type:
- Research Manuscript
- Document Year:
- 2024
- Event:
- Presenters:
- Vasilis Tsouvalas
- Paper Code:
- MLSP-P10.3
- Categories:
- Log in to post comments
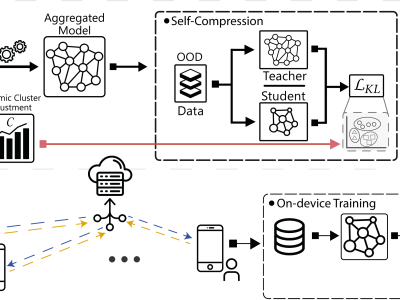
Federated Learning (FL) is a promising technique for the collaborative training of deep neural networks across multiple devices while preserving data privacy. Despite its potential benefits, FL is hindered by excessive communication costs due to repeated server-client communication during training. To address this challenge, model compression techniques, such as sparsification and weight clustering are applied, which often require modifying the underlying model aggregation schemes or involve cumbersome hyperparameter tuning, with the latter not only adjusts the model's compression rate but also limits model's potential for continuous improvement over growing data. In this paper, we propose FedCompress, a novel approach that combines dynamic weight clustering and server-side knowledge distillation to reduce communication costs while learning highly generalizable models. Through a comprehensive evaluation on diverse public datasets, we demonstrate the efficacy of our approach compared to baselines in terms of communication costs and inference speed. Our code is available at https://github.com/FederatedML/FedCompress

