Documents
Poster
A Deep Generative Model of Speech Complex Spectrograms
- Citation Author(s):
- Submitted by:
- Aditya Arie Nugraha
- Last updated:
- 12 May 2022 - 12:59am
- Document Type:
- Poster
- Document Year:
- 2019
- Event:
- Presenters:
- Aditya Arie Nugraha
- Paper Code:
- AASP-P14
- Categories:
- Log in to post comments
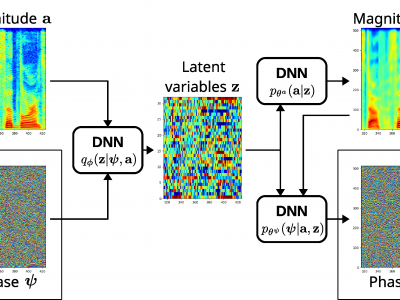
This paper proposes an approach to the joint modeling of the short-time Fourier transform magnitude and phase spectrograms with a deep generative model. We assume that the magnitude follows a Gaussian distribution and the phase follows a von Mises distribution. To improve the consistency of the phase values in the time-frequency domain, we also apply the von Mises distribution to the phase derivatives, i.e., the group delay and the instantaneous frequency. Based on these assumptions, we explore and compare several combinations of loss functions for training our models. Built upon the variational autoencoder framework, our model consists of three convolutional neural networks acting as an encoder, a magnitude decoder, and a phase decoder. In addition to the latent variables, we propose to also condition the phase estimation on the estimated magnitude. Evaluated for a time-domain speech reconstruction task, our models could generate speech with a high perceptual quality and a high intelligibility.

