Documents
Presentation Slides
Deep Metric Learning using Similarities from Nonlinear Rank Approximations
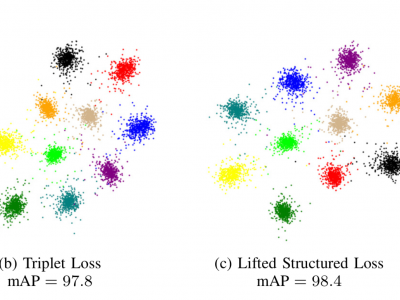
- Citation Author(s):
- Submitted by:
- Kai Barthel
- Last updated:
- 27 September 2019 - 10:06pm
- Document Type:
- Presentation Slides
- Document Year:
- 2019
- Event:
- Presenters:
- Kai Uwe Barthel
- Categories:
- Keywords:
- Log in to post comments
In recent years, deep metric learning has achieved promising results in learning high dimensional semantic feature embeddings where the spatial relationships of the feature vectors match the visual similarities of the images. Similarity search for images is performed by determining the vectors with the smallest distances to a query vector. However, high retrieval quality does not depend on the actual distances of the feature vectors, but rather on the ranking order of the feature vectors from similar images. In this paper, we introduce a metric learning algorithm that focuses on identifying and modifying those feature vectors that most strongly affect the retrieval quality. We compute normalized approximated ranks and convert them to similarities by applying a nonlinear transfer function. These similarities are used in a newly proposed loss function that better contracts similar and disperses dissimilar samples. Experiments demonstrate significant improvement over existing deep feature embedding methods on the CUB-200-2011, Cars196, and Stanford Online Products data sets for all embedding sizes.

