
MMSP 2019 is the IEEE 21st International Workshop on Multimedia Signal Processing. The workshop is organized by the Multimedia Signal Processing Technical Committee (MMSP TC) of the IEEE Signal Processing Society (SPS). The workshop will bring together researcher and developers from different fields working on multimedia signal processing to share their experience, exchange ideas, explore future research directions and network.

- Read more about Super-resolution of Omnidirectional Images Using Adversarial Learning
- Log in to post comments
An omnidirectional image (ODI) enables viewers to look in every direction from a fixed point through a head-mounted display providing an immersive experience compared to that of a standard image. Designing immersive virtual reality systems with ODIs is challenging as they require high resolution content. In this paper, we study super-resolution for ODIs and propose an improved generative adversarial network based model which is optimized to handle the artifacts obtained in the spherical observational space.
- Categories:
 81 Views
81 Views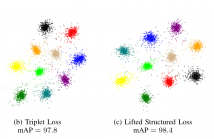
- Read more about Deep Metric Learning using Similarities from Nonlinear Rank Approximations
- Log in to post comments
In recent years, deep metric learning has achieved promising results in learning high dimensional semantic feature embeddings where the spatial relationships of the feature vectors match the visual similarities of the images. Similarity search for images is performed by determining the vectors with the smallest distances to a query vector. However, high retrieval quality does not depend on the actual distances of the feature vectors, but rather on the ranking order of the feature vectors from similar images.
- Categories:
66 Views
- Read more about 3D Facial Expression Recognition Based on Multi-View and Prior Knowledge Fusion
- Log in to post comments
MMSP2019.pdf
- Categories:
33 Views
- Read more about Selective Hearing: A Machine Listening Perspective
- Log in to post comments
Selective hearing (SH) refers to the listeners' capability to focus their attention on a specific sound source or a group of sound sources in their auditory scene. This in turn implies that the listeners' focus is minimized for sources that are of no interest.
This paper describes the current landscape of machine listening research, and outlines ways in which these technologies can be leveraged to achieve SH with computational means.
- Categories:
79 Views
- Read more about Lowering Dynamic Power of a Stream-based CNN Hardware Accelerator
- Log in to post comments
Custom hardware accelerators of Convolutional Neural Networks (CNN) provide a promising solution to meet real-time constraints for a wide range of applications on low-cost embedded devices. In this work, we aim to lower the dynamic power of a stream-based CNN hardware accelerator by reducing the computational redundancies in the CNN layers. In particular, we investigate the redundancies due to the downsampling effect of max pooling layers which are prevalent in state-of-the-art CNNs, and propose an approximation method to reduce the overall computations.
- Categories:
87 Views
Inserting a logo into HEVC video streams is highly demanded in video applications. In this paper, we present an efficient logo insertion method for video coding in HEVC. To reduce the impact of inserted logo, the proposed method mitigates the encoding dependence on logo by partitioning the video frame into separated regions. For lossless coding region, we reduce the bit rate overhead of lossless coding according to an error propagation model. For information reusing region, we partly re-encode the quality-loss area to maintain the encoding quality.
Oral.pptx
- Categories:
24 Views
- Read more about Deep Aggregation of Regional Convolutional Activations for Content Based Image Retrieval
- Log in to post comments
One of the key challenges of deep learning based image retrieval remains in aggregating convolutional activations into one highly representative feature vector. Ideally, this descriptor should encode semantic, spatial and low level information. Even though off-the-shelf pre-trained neural networks can already produce good representations in combination with aggregation methods, appropriate fine tuning for the task of image retrieval has shown to significantly boost retrieval performance.
- Categories:
52 Views
- Read more about Luminance-based Video Backdoor Attack Against Anti-spoofing Rebroadcast Detection
- 1 comment
- Log in to post comments
MMSP2019.pdf
- Categories:
51 Views
- Read more about Lightweight Deep Convolutional Neural Networks for Facial Epression Recognition
- Log in to post comments
- Categories:
38 Views
- Read more about Multi-Label Classification for Automatic Human Blastocyst Grading with Severely Imbalanced Data
- Log in to post comments
Quality scores assigned to blastocyst inner cell mass (ICM), trophectoderm (TE), and zona pellucida (ZP) are critical markers for predicting implantation potential of a human blastocyst in IVF treatment. Deep Convolutional Neural Networks (CNNs) have shown success in various image classification tasks, including classification of blastocysts into two quality categories. However, the problem of multi-label multi-class classification for blastocyst grading remains unsolved.
- Categories:
94 Views