
- Read more about Supplementary Materials of FaceLiVT: Face Recognition using Linear Vision Transformer with Structural Reparameterization
- Log in to post comments
This paper presents FaceLiVT, a lightweight yet powerful face recognition model that combines a hybrid CNN- Transformer architecture with an innovative and lightweight Multi-Head Linear Attention (MHLA) mechanism. By incorporating MHLA alongside a reparameterized token mixer, FaceLiVT effectively reduces computational complexity while preserving high accuracy. Extensive evaluations on challenging benchmarks—including LFW, CFP-FP, AgeDB-30, IJB-B, and IJB-C—highlight its superior performance compared to state-of-the-art lightweight models.
- Categories:
 62 Views
62 Views
- Read more about NEURAL RESTORATION OF GREENING DEFECTS IN HISTORICAL AUTOCHROME PHOTOGRAPHS BASED ON PURELY SYNTHETIC DATA
- Log in to post comments
The preservation of early visual arts, particularly color photographs, is challenged by deterioration caused by aging and improper storage, leading to issues like blurring, scratches, color bleeding, and fading defects. In this paper, we present the first approach for the automatic removal of greening color defects in digitized autochrome photographs. Our main contributions include a method based on synthetic dataset generation and the use of generative AI with a carefully designed loss function for the restoration of visual arts.
- Categories:
27 Views
- Read more about EXPLOITATION OF OPEN SOURCE DATASETS AND DEEP LEARNING MODELS FOR THE DETECTION OF OBJECTS IN URBAN AREAS
- Log in to post comments
In this work we utilize different open-source datasets and deep learning models for detecting objects from image data captured by a mobile mapping system integrating the multi-camera Ladybug 5+ in an urban area. In our experiments
we exploit sets of pre-trained models and models trained via transfer learning techniques with available open source datasets for object detection, semantic-, instance-, and panoptic segmentation. Tests with the trained models are performed with image data from the Ladybug 5+ camera.
- Categories:
27 Views- Read more about LIGHTWEIGHT UNDERWATER IMAGE ENHANCEMENT VIA IMPULSE RESPONSE OF LOW-PASS FILTER BASED ATTENTION NETWORK
- Log in to post comments
In this paper, we propose an improved model of Shallow-UWnet for underwater image enhancement. In the proposed method, we enhance the learning process and solve the vanishing gradient problem by a skip connection, which concatenates the raw underwater image and the low-pass filter (LPF) impulse response into Shallow-UWnet. Additionally, we integrate the simple, parameter-free attention module (SimAM) into each Convolution Block to enhance the visual quality of images.
- Categories:
61 Views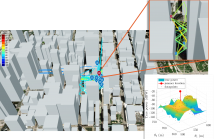
- Read more about JAMMING SOURCE LOCALIZATION USING AUGMENTED PHYSICS-BASED MODEL
- Log in to post comments
Monitoring interferences to satellite-based navigation systems is of paramount importance in order to reliably operate critical infrastructures, navigation systems, and a variety of applications relying on satellite-based positioning. This paper investigates the use of crowdsourced data to achieve such detection and monitoring at a central node that receives the data from an arbitrary number of agents in an area of interest. Under ideal conditions, the pathloss model is used to compute the Cramér-Rao Bound of accuracy as well as the corresponding maximum likelihood estimator.
- Categories:
38 Views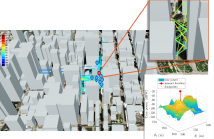
- Read more about JAMMING SOURCE LOCALIZATION USING AUGMENTED PHYSICS-BASED MODEL
- Log in to post comments
Monitoring interferences to satellite-based navigation systems is of paramount importance in order to reliably operate critical infrastructures, navigation systems, and a variety of applications relying on satellite-based positioning. This paper investigates the use of crowdsourced data to achieve such detection and monitoring at a central node that receives the data from an arbitrary number of agents in an area of interest. Under ideal conditions, the pathloss model is
- Categories:
34 Views
- Read more about PRE-ECHO REDUCTION IN TRANSFORM AUDIO CODING VIA TEMPORAL ENVELOPE CONTROL WITH MACHINE LEARNING BASED ESTIMATION
- Log in to post comments
This paper proposes a new method for pre-echo reduction in transform-based audio coding by controlling the temporal envelope of the waveform. The proposed method comprises two operating modes: temporal envelope flattening and temporal envelope correction of a target signal. The proposed method estimates signal levels with a low temporal resolution from side information using machine learning and converts them into a signal to be applied to the target signal to flatten and correct the temporal envelope.
- Categories:
54 Views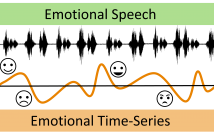
- Read more about Dynamic Speech Emotion Recognition using a Conditional Neural Process
- Log in to post comments
The problem of predicting emotional attributes from speech has often focused on predicting a single value from a sentence or short speaking turn. These methods often ignore that natural emotions are both dynamic and dependent on context. To model the dynamic nature of emotions, we can treat the prediction of emotion from speech as a time-series problem. We refer to the problem of predicting these emotional traces as dynamic speech emotion recognition. Previous studies in this area have used models that treat all emotional traces as coming from the same underlying distribution.
- Categories:
115 Views
- Read more about MLSP-L18.6 presentation
- Log in to post comments
Efficient training of large-scale graph neural networks (GNNs) has been studied with a specific focus on reducing their memory consumption. Work by Liu et al. (2022) proposed extreme activation compression (EXACT) which demonstrated drastic reduction in memory consumption by performing quantization of the intermediate activation maps down to using INT2 precision. They showed little to no reduction in performance while achieving large reductions in GPU memory consumption.
- Categories:
33 Views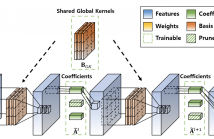
- Read more about G-SharP: Globally Shared Kernel with Pruning for Efficient CNNs
- Log in to post comments
Filter Decomposition (FD) methods have gained traction in compressing large neural networks by dividing weights into basis and coefficients. Recent advancements have focused on reducing weight redundancy by sharing either basis or coefficients stage-wise. However, traditional sharing approaches have overlooked the potential of sharing basis on a network-wide scale. In this study, we introduce an FD technique called G-SharP that elevates performance by using globally shared kernels throughout the network.
- Categories:
39 Views