Documents
Poster
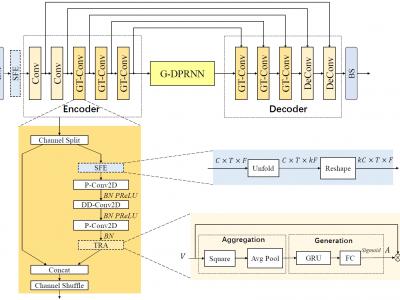
GTCRN: A Speech Enhancement Model Requiring Ultralow Computational Resources
- DOI:
- 10.60864/6hrq-vg93
- Citation Author(s):
- Submitted by:
- Xiaobin Rong
- Last updated:
- 6 June 2024 - 10:54am
- Document Type:
- Poster
- Document Year:
- 2024
- Event:
- Presenters:
- Xiaobin Rong
- Paper Code:
- AASP-P2.3
- Categories:
- Log in to post comments
While modern deep learning-based models have significantly outperformed traditional methods in the area of speech enhancement, they often necessitate a lot of parameters and extensive computational power, making them impractical to be deployed on edge devices in real-world applications. In this paper, we introduce Grouped Temporal Convolutional Recurrent Network (GTCRN), which incorporates grouped strategies to efficiently simplify a competitive model, DPCRN. Additionally, it leverages subband feature extraction modules and temporal recurrent attention modules to enhance its performance. Remarkably, the resulting model demands ultralow computational resources, featuring only 23.7 K parameters and 39.6 MMACs per second. Experimental results show that our proposed model not only surpasses RNNoise, a typical lightweight model with similar computational burden, but also achieves competitive performance when compared to recent baseline models with significantly higher computational resources requirements.

