Documents
Poster
Neural Audio Fingerprint for High-specific Audio Retrieval based on Contrastive Learning
- Citation Author(s):
- Submitted by:
- Sungkyun Chang
- Last updated:
- 7 July 2021 - 2:18pm
- Document Type:
- Poster
- Document Year:
- 2021
- Event:
- Presenters:
- Sungkyun Chang
- Paper Code:
- MLSP-11.1
- Categories:
- Log in to post comments
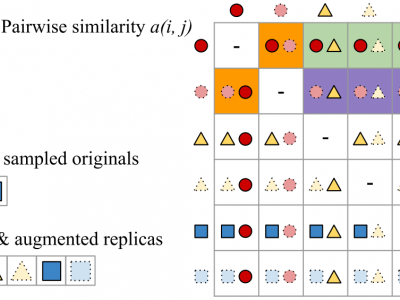
Most of existing audio fingerprinting systems have limitations to be used for high-specific audio retrieval at scale. In this work, we generate a low-dimensional representation from a short unit segment of audio, and couple this fingerprint with a fast maximum inner-product search. To this end, we present a contrastive learning framework that derives from the segment-level search objective. Each update in training uses a batch consisting of a set of pseudo labels, randomly selected original samples, and their augmented replicas. These replicas can simulate the degrading effects on original audio signals by applying small time offsets and various types of distortions, such as background noise and room/microphone impulse responses. In the segment-level search task, where the conventional audio fingerprinting systems used to fail, our system using 10x smaller storage has shown promising results. Our code and dataset are available at https://mimbres.github.io/neural-audio-fp/.

