Documents
Presentation Slides
Parallel waveform synthesis based on generative adversarial networks with voicing-aware conditional discriminators
- Citation Author(s):
- Submitted by:
- Ryuichi Yamamoto
- Last updated:
- 26 June 2021 - 2:38am
- Document Type:
- Presentation Slides
- Document Year:
- 2021
- Event:
- Presenters:
- Ryuichi Yamamoto
- Categories:
- Log in to post comments
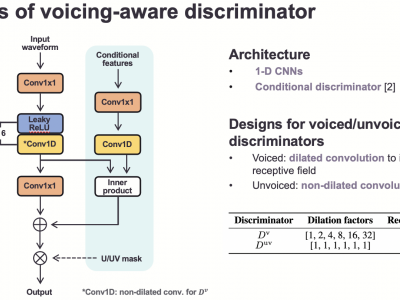
This paper proposes voicing-aware conditional discriminators for Parallel WaveGAN-based waveform synthesis systems. In this framework, we adopt a projection-based conditioning method that can significantly improve the discriminator's performance. Furthermore, the conventional discriminator is separated into two waveform discriminators for modeling voiced and unvoiced speech. As each discriminator learns the distinctive characteristics of the harmonic and noise components, respectively, the adversarial training process becomes more efficient, allowing the generator to produce more realistic speech waveforms. Subjective test results demonstrate the superiority of the proposed method over the conventional Parallel WaveGAN and WaveNet systems. In particular, our speaker-independently trained model within a FastSpeech 2 based text-to-speech framework achieves the mean opinion scores of 4.20, 4.18, 4.21, and 4.31 for four Japanese speakers, respectively.

