Documents
Poster
Poster: Synchformer: Efficient Synchronization from Sparse Cues
- DOI:
- 10.60864/v8m9-j241
- Citation Author(s):
- Submitted by:
- Vladimir Iashin
- Last updated:
- 6 June 2024 - 10:27am
- Document Type:
- Poster
- Document Year:
- 2024
- Event:
- Presenters:
- Vladimir Iashin
- Paper Code:
- MLSP-P4.1
- Categories:
- Keywords:
- Log in to post comments
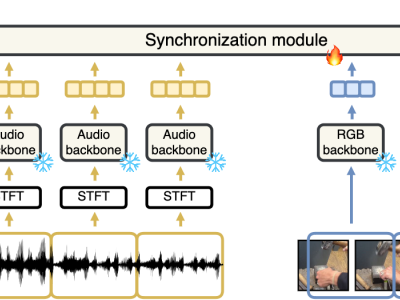
Our objective is audio-visual synchronization with a focus on ‘in-the-wild’ videos, such as those on YouTube, where synchronization cues can be sparse. Our contributions include a novel audio-visual synchronization model, and training that decouples feature extraction from synchronization modelling through multi-modal segment-level contrastive pre-training. This approach achieves state-of-the-art performance in both dense and sparse settings. We also extend synchronization model training to AudioSet a million-scale ‘in-the-wild’ dataset, investigate evidence attribution techniques for interpretability, and explore a new capability for synchronization models: audio-visual synchronizability. Code, models, and project page: https://www.robots.ox.ac.uk/~vgg/research/synchformer/

